

Introduction
Tesseract engine optical character recognition (OCR) is a technology used to convert scanned paper documents, PDF files, and images to searchable text data. The OCR engine detects the characters present in the image and puts those characters into words, enabling developers to search and edit the content of the document. Tesseract optical character recognition engine is one of the most accurate OCR engines currently available for .NET. It’s licensed under Apache 2.0 and has been supported by Google since 2006. Tesseract OCR library is available for various different operating systems. In this article, I will demonstrate extracting image text using Tesseract and writing C# code under Windows OS. If you find yourself struggling with C# or want to increase your knowledge, consider visiting the TechRepublic Academy!
.NET Application to Extract Text from an Image
For optical character recognition, we will be using the Tesseract.NET SDK. Tesseract.NET SDK is a class library based on the tesseract-ocr project. It can read a wide variety of image formats and convert them to text in over 60 languages.
To develop the sample application, we will need Visual Studio and a basic knowledge of C# programming. I will be using Visual Studio 2015 with .NET Framework 4.5.
From the Visual Studio New Project window, select Visual C#> Windows> Console Application and provide a name to the project—I called it “ProjectTesseract”—and save it. You can see this in Figure 1.
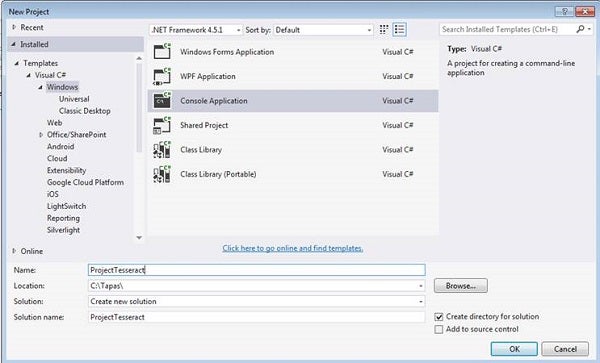
Figure 1: Visual Studio New Console Project
Figure 2 is the screen shot of the console application project.
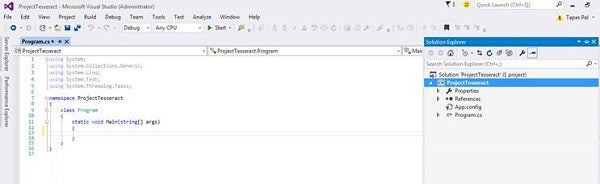
Figure 2: Visual Studio Sample Project Code
Next, open NuGet Package Manager Console.
To open the NuGet Manager, go to TOOLS> Library Package Manager> Package Manager Console, as indicated in Figure 3. You can open this by right-clicking the project and selecting Manage NuGet package.
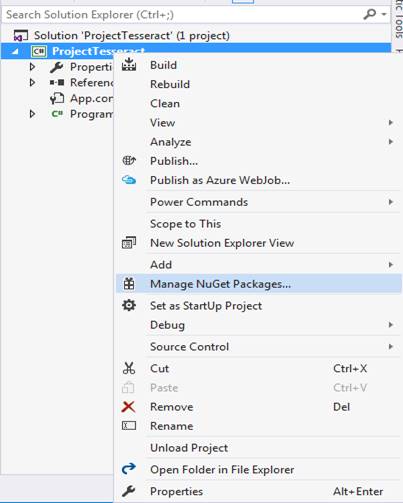
Figure 3: Visual Studio NuGet Package Manager
Next, Install Tesseract.Net SDK through the Package Manager Console.
Run the command in Package Manager Console to install Tesseract.NET SDK or Select the NuGet package and install. Refer to Figures 4 and 5.
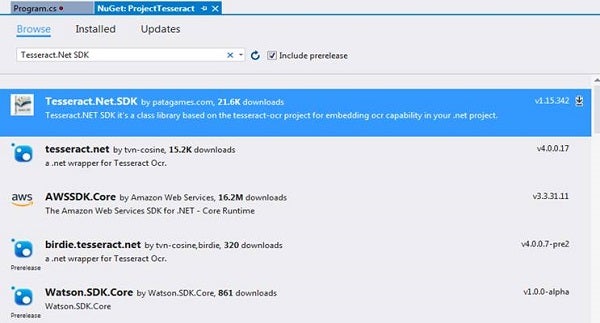
Figure 4: NuGet Package Manager with Tesseract.NET SDK
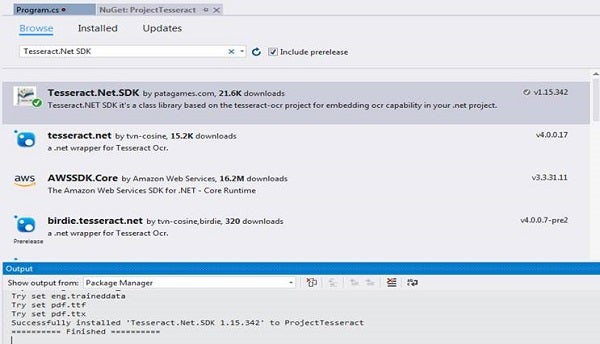
Figure 5: NuGet Package Manager with Tesseract.NET SDK
After successful installation, Tesseract SDK will add the following DLLs in your project. Also, a specific folder structure will be created.
- Patagames.Ocr.dll contains OCR API Class
- Patagames.Ocr.xml contains XML documentation of the API
- x86\tesseract.dll is the 32-bit version of the Tesseract library
- x64\tesseract.dll is the 64-bit version of the Tesseract library
The tessdata installed folder contains all files required for the Tesseract engine to work in the .NET Project.
Now, let’s create the console application. First, I have created an instance of OcrApi class to use Tesseract.NET API in the application. Refer to the following code snippet.
using Patagames.Ocr;
var api = OcrApi.Create();
Next, refer to the typical C# code demonstrating how to extract plain text from the image. The following code snippet explains how to create an instance of the OcrApi class and initialize it for the English language. Then, I simply get the text from the image.
The GetTextFromImage() method extracts text from .PNG, .BMP, and .JPEG images. Also remember, the result of the OCR also changes with the quality of the image. GetTextFromImage method can recognize text on a given bitmap, for instance System.Drawing.Bitmap.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Drawing;
using Patagames.Ocr;
using Patagames.Ocr.Enums;
namespace ProjectTesseract
{
public class Program
{
static void Main(string[] args)
{
Program obj = new Program();
obj.ConvertImageToText();
}
public void ConvertImageToText()
{
using (var api = OcrApi.Create())
{
api.Init(Languages.English);
string plainText = api.GetTextFromImage("C:\\Tapas\\
Downloads\\Image.jpg");
Console.WriteLine(plainText);
Console.Read();
}
}
}
}
We can also create a searchable PDF from scanned images, not plain text. Refer to the following code snippet that demonstrates PDF creation.
public void TifftoPdfConvertion()
{
using (var api = OcrApi.Create())
{
api.Init(Languages.English);
using (var renderer = OcrPdfRenderer.
Create("multipagepdffile", @"C:\\Tapas\\Downloads"))
{
renderer.BeginDocument("Title");
api.ProcessPages(@"C:\Tapas\multidocs.tif", null, 0,
renderer);
renderer.EndDocument();
}
}
}
Conclusion
I hope this article has helped you understand the basic concept of extracting text from an image using Tesseract in C#. Please provide your valuable feedback for improvement. That’s all for today; happy reading!