

Introduction
A Performance engineering engagement has been conducted for one of the leading automobile insurance companies in Canada. As per the customer decision to reduce the operational and maintenance expenditure, the data residing in different data stores such as DB2 and Oracle is transferred to a consolidated repository maintained in SQL Server 2008. The existing Java client applications communicating with either DB2/Oracle 10g are remediated to communicate with SQL Server.
Though the modified environment could meet the functional expectations, there were some setbacks in the application behavior in terms of performance and scalability.
It was observed that most of the performance issues addressed as part of this exercise could be quite common across any data migration project to SQL Server. The basic idea of preparing this artifact is to address these reoccurring performance issues, thus saving the potential risks & execution effort.
Environment Details

Tools Used
Performance Sensitive Areas in Migration
The points mentioned below are the performance sensitive areas that need to be monitored on data migration to SQL server.
* If the client is Java related, communication between client and SQL Server
* Row level triggers in SQL Server
* Referential integrity through triggers in SQL Server
* Multiple after triggers and rollbacks
* Recursive and nested triggers in SQL Server
* Extended stored procedures
* Nested cursors
* Case-sensitivity and collation
Each of these topics will be discussed in detail.
Communication Between Java Client and SQL Server
The end to end transaction from java client to SQL server was taking more than 20 min to respond. Though Java client has inline queries (dynamic SQL), the same transaction was taking around 5 sec in the existing application.
Below are the observation made:
* The SQL trace captured depicted that most of the queries execution time was higher along with the high disk reads and writes.
* The queries execution time was higher even when fired from the backend.
* Table scans were occurring for most of the queries.
On remediating the necessary indexes manually on SQL Server, table scans and query execution times triggered at the back end are minimized. This could reduce the transaction time from 20 min to around 8 min, still way ahead of the SLA.
Apart from the missing index issue identified, the transaction was still taking more time to execute when triggered from the front-end. The pattern below has been noticed in the SQL trace when queries are being fired using JDBC drivers for the time consuming transactions.
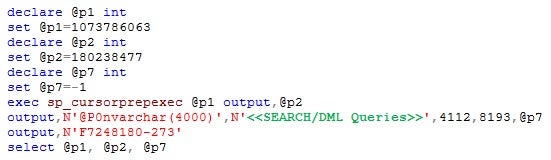
From this pattern, it is obvious that communication between the Java application and SQL Server is happening using Unicode (NVARCHAR in red)
There could be a performance problem with respect to communication between a Java client and the SQL Server using Java drivers. Most of the Java drivers pass string parameters to SQL Server as Unicode, by default. The problem here is, if the Unicode parameters reference VARCHAR key columns in an index, SQL Server engine will not use the appropriate index for query resolution, thereby increasing the unwanted table scans.
This can be corrected by resetting one of the default parameters in the Java driver. The parameter name and value to be set might vary from driver to driver, depending on vendor.

The below statistics are captured by running one of the queries used by the transaction, with both “sendStringParametersAsUnicode” as true and false:

By making this change the transaction that was taking around 8 min reduced drastically to 5 sec.
Row Level Triggers in SQL Server
One of the major differences between Oracle and SQL Server triggers is that the most common Oracle trigger is a row-level trigger (FOR EACH ROW) that initiates for each row of the source statement. SQL Server supports only statement-level triggers, which fire only once per statement, regardless of the total number of rows affected. The basic conversion rules used by SSMA for Oracle for triggers conversion are (As per SSMA for Oracle conversion guide):
1. All BEFORE triggers for a table are converted into one INSTEAD OF trigger.
2. AFTER triggers remain AFTER triggers in SQL Server.
3. INSTEAD OF triggers on Oracle views remain INSTEAD OF triggers.
4. Row-level triggers are outdone with a cursor loop.
Each trigger initiated acquires a lock on the table and is released once the action is complete. Even with the least resource intensive cursor configuration (FAST FORWARD, READ ONLY), the performance of the trigger might be affected by the following:
* Number of rows iterated through the cursor
* SQL statements against other tables external to the inserted or deleted tables.
Locking issues or hanging of batch execution has been observed at many instances in the transaction flow, for row level triggers with cursors.
Microsoft also recommends minimizing the cursor usage whereever applicable, due to their high resource consumption nature. The best practice is to keep the trigger logic simple. If the business case is to loop across the modified rows inside the trigger, table variables (temp tables) or row set logic would be preferred over cursors.