


We all know the scenario: The boss has come downstairs and asked you to process some data for him. Sure you say, it’s no problem. Email me a copy of the data, and I’ll do what I need to then email you the results back. Ten minutes later, you get an email entitled “Here’s the data you requested.” Great, you think to yourself; I’ll hack a quick WinForms application together, load the data in, process it, and send it back out. It’ll only take me an hour.
Then you open the email…
and all that’s there is a URL:
http://www.competitorssite.co.uk/data
To make matters worse, the site requires you create a log-in before you get access to the data, and your quick one hour job now looks like it’s going to take you the best part of a day.
A Common Occurrence
To the management types, data is data. It doesn’t matter where it comes from, how they came by it, or what shape it’s in. It’s all the same to them.
Because of this fact, as far as they’re concerned it should take you exactly the same amount of time to process it irrespective of if you have to yank it out of a web page beforehand, or whether you already have it available in a nice handy CSV format. If you have to also log in to a site to get the data, you might also be thinking, how on earth am I going to automate the log in (because you just know that if you do this, it’s going to become a weekly job), you need to parse the code.
You could write a web application, and then hope that you can make a cross site request and pull the data out using jQuery. That might work, but do you really want to try and automate the login this way? It might surprise you, however, that .NET actually has everything available that you need to perform this task easily in the form of the web browser control.
A Practical Example
Fire up Visual Studio (I’m using VS2013) and create yourself a web-forms project. Once the project is created and you have a blank window on the screen in front of you, stretch the window out to a reasonable size (Say 1024×768 ish).
Drag yourself a button and a web browser control onto your form, place the button somewhere near the top, and then let the web browser control occupy the rest. You should have something that looks similar to Figure 1.
Figure 1: The initial Webforms project
Double-click your button, and add the following code into the button handler.
private void button1_Click(object sender, EventArgs e)
{
webBrowser1.Navigate("http://stackoverflow.com");
}
Press F5 to run your program. Click the button and the browser control should display the main stack overflow web page (see Figure 2).
Figure 2: The main stack overflow web page
You’ll notice that the page you get is the generic, not logged in, version. If you look at the events available for the web browser control, you should see that there’s one available that tells you when the navigation of the page is complete.
Like the jQuery document ready function, this fires when the page has fully loaded and is ready for you to access the web page data directly. We can use this to tell us when it’s safe to grab a copy of the web page contents. To do this, add the following code to your forms class.
protected string pageContent;
private void webBrowser1_DocumentCompleted(object sender,
WebBrowserDocumentCompletedEventArgs e)
{
pageContent = webBrowser1.DocumentText;
MessageBox.Show("Document text retrieved");
}
Then, wire up the “Document Completed” event handler to the same event on your web browser control. Run the app again, and this time you should get an alert once the page is loaded.
If you place a break point and look at your string variable called pageContent, you should find that you have a copy of the page’s HTML in there, ready to manipulate.
At this point, we could easily pull apart this string using regex’es, or dedicated html libraries such as “HTML Agility”, for most of us these days though where so used to using a selector based approach that manual parsing of HTML data is now something we’d rather run away from.
As with everything .NET, however, if we don’t have anything in the base library to help us, then there will almost definitely be something in NuGet. Right-click your project node, go to manage NuGet packages, and then search for and install “CsQuery”
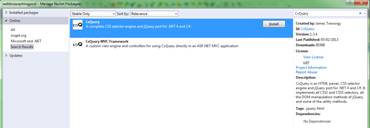
Figure 3: Installing CsQuery
CsQuery is actually a .NET port of the actual jQuery sources; it’s not an imitation or a compatible library. The author has used the actual jQuery source code to create a .NET4 version that works in an almost identical manner (at least as far as the CSS selector engine is concerned, anyway). What this means is that any selector route you might take when using jQuery to extract an element of an HTML dom from a web page, you can now do on any suitable HTML source directly in a .NET application.
For the purposes of this article, we’re going to parse out the list of questions available from the front page of stack overflow. If you look at the source code for this page, you’ll find that each row in the question list is wrapped in the following div tag:
<div class="question-summary narrow"
id="question-summary-26453842">
...
</div>
The ID is unique for each question in the list, but each row of the list has a ‘question-summary’ class applied to it. If we get a list of all the div tags with that class applied, we’ll have a list of HTML elements that contain only the data we want to extract from the document.
Add the following lines of code to your “Document loaded” handler after first removing the alert box call to show it’s loaded.
CQ dom = pageContent;
CQ questions = dom["div.question-summary"];
If you place a break point on the first of those lines and run the app, you should find that when you load the document and reach there, you now have a collection containing all the questions available on the page.
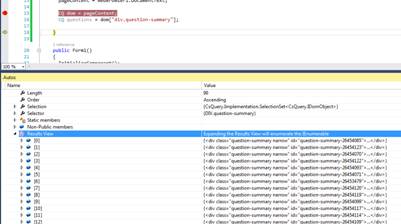
Figure 4: All the questions available on the page
Not a bad start for three lines of code!!
Because we now have a list that we can enumerate over, we can wrap each of these in a for each loop and further break down the rows to get exactly the data we want. I’m not going to paste the full HTML into this article, but if we go back to the HTML source code and look at the inner contents of each row, we can see a few more common things that stand out. For starters, the first div that is a child of the row, is a div with a class of “cp”; more importantly, however, is that this div has an onclick handler that sends the browser to the page for the question.
<div onclick="window.location.href='/questions/26453842/
powerful-way-to-save-dom-elements-in-an-object'"
class="cp">
If we were to grab the contents of the onclick attribute from this div, and then remove everything before the = followed by the = itself and the enclosing ‘ marks, we immediately have that URL. The next div holds the votes for the question, which further holds nested divs for the different vote counts.
For this demo, though, all were interested in is the question text; that can be found a little further down in a div with a class of “summary”. This div contains an H3 tag that wraps an anchor tag, which in turn has a title attribute containing the question text and the URL of the page.
Just as we might chain selectors in jQuery, we can also do the same using CsQuery. First, we need to foreach over each row, and then we need to target and extract the selector that gets us the anchor tag containing our attributes. Once we isolate the anchor tag, we then extract the attribute values and save them somewhere.
First, let’s add a new class to our application, something like the following:
namespace webbrowserblogpost
{
public class SoQuestion
{
public string QuestionTitle { get; set; }
public string Url { get; set; }
public string QuestionSummary { get; set; }
}
}
Now, add the following code to our document loaded handler to extract and store our data.
List<SoQuestion> questionData = new List<SoQuestion>();
foreach(var question in questions)
{
CQ innerHtml = question.InnerHTML;
string link = innerHtml["div.summary > h3 > a"].Attr("href");
string summary = innerHtml["div.summary > h3 > a"].Attr("title");
string title = innerHtml["div.summary > h3 > a"].Text();
questionData.Add(new SoQuestion
{
QuestionTitle = title,
QuestionSummary = summary,
Url = link
});
}
If you now put a break point on the end of your document loaded handler, you should find you have a list of titles & URLs of each of the questions.

Figure 5: A list of titles and URLs of each of the questions
And that’s it. You’ve successfully gotten the data you want, with about 10 minutes’ work and about 15 lines of code. Of course, you could make the code denser by using Linq on the loop, and getting rid of some of the fluff, but even with what we have, it’s elegant and works a treat.
If you attempt to retrieve the value of an attribute, or element contents that do not exist, CsQuery will silently convert the return to a null; it won’t throw an exception, or abort the parse. You’ll simply just not get what you requested, and because you’re looking for strings, you can handle them with ease all the way through to the database if needed.
There’s still one more thing to cover though.
Logging in and authenticating.
Because the web browser control uses Internet Explorer as its base, any cookies or anything that are saved from a given site will remain available, even in future invocations of the web browser component. What this means, in practice, is you can use a visible web browser control to log in, aand then you can run the rest of your application with a web browser control created on the fly in code, that will then extract the wanted data and process/save it as needed all while still being logged in.
I’ve used this approach in many places, where I’ve created a command line app with a ‘/gui’ switch. When the app is run specifying the gui switch, it opens a windows form with the login page of the site displayed. The user then logs in and exits the app. The next time the app is run, it realises the site is logged in and just goes ahead extracts its data and saves it.
If you have any burning questions, or you want to make a comment on this article, please feel free to use the comments section below of come find me on the internet. I can usually be found in the Lidnug (Linked .NET users group on Linked-in) which I help run, or floating around on Twitter as @shawty_ds.