

Thread pooling describes a technique by which threads of execution are managed and to which work is distributed. Additional semantics such as concurrency control may also be defined. Thread pooling is a nice way to perform the following tasks:
Manage complexity
Thread pooling is a natural fit for state-based processing. if you can decompose your system into a set of state machines, thread pooling works nicely and effectively in realizing your design. This provides the added benefit of simplifying the debugging of multithreaded applications in most cases.
Make your applications scalable
Properly implemented, the thread pool can enforce concurrency limits that will make your application scalable.
Introduce new code while minimizing risk
Thread pooling lets you break execution into work units that are best described as development sandboxes. Sandboxes are fun and safe! How? Thread pooling promotes loose coupling between processes and naturally separates data from process. Any coupling between processes typically happens at a well-defined data point. This can be a lot easier to maintain over time, especially in large multithreaded applications.
Design
The conceptual model of a thread pool is simple: The pool starts threads running; work is queued to the pool; available threads execute the queued work. By using templates, the pool may be defined independent of the thread/work implementation (a technique known as static polymorphism).
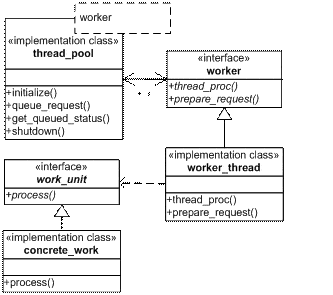
Figure 1. Thread pool collaboration diagram
The thread pool is responsible for thread creation; threads commence execution at worker::thread_proc. Requests are queued to the thread pool; the worker prepares the request and the request is queued. When a thread is available to process the work, it may request the pending work from the thread pool with thread_pool::get_queued_status. If there is no pending work, the thread is suspended until work is available.
Chaining
While our worker implementation allows us to queue work, we can go one step further. The thread pool promises to help us break problems into discrete steps that maintain state minimizing complexity and risk while maximizing the raw power we can squeeze out of our box. However, our current implementation only allows us to queue one piece of work at a time, making it cumbersome to logically group sequential work together. We also need some way of knowing when that work is done so that we might queue some more work.
The example:
Take the system down; rebuild the system data; bring the system back online.
Three steps, three pieces of work. I would like to be able to use this instead[1]:
thread_pool::instance().queue_request(
(core::chain(), new system_down, new rebuild_data,
new system_up));
What is chain? A work unit! Rather, our chain simply acts as a container for the real work unit, which in turn is just a container of work units:
struct chain {
struct data : work_unit, std::list<smart_pointer<work_unit> > {
void process();
};
chain() : m_work(new data) {}
chain& operator,(work_unit* p_work);
operator work_unit*() { return m_work; }
smart_pointer<data> m_work;
}; // struct chain
chain::operator does just as advertised:
m_work->push_back(p_work);
return *this;
chain::data::process() is just as simple:
front()->process();
pop_front();
// if not empty, requeue
if (true == empty()) return;
thread_pool<worker_thread>::instance().queue_request(this);
Using the Code
Initialize the thread pool you want to use. Because thread pools are parameterized singletons, there will be a thread pool instance for each type of worker used. The global::thread_pool class is a convenient typedef for core::thread_pool<core::worker_thread>.
global::thread_pool::instance().initialize();
If you choose core::worker_thread as your worker implementation, all work will be derived from core::work_unit and your work will be performed when the process is called.
struct mywork : core::work_unit
{
void process() throw()
{
// work is processed here
}
}
To queue work, create an instance of your class and initialize it as necessary. Use thread_pool::queue_request to queue the work.
// demonstrate chaining
global::thread_pool::instance().queue_request(
(core::chain(), new work_1, new work_2, new work_3));
To shut down the thread pool, use thread_pool::shutdown.
global::thread_pool::instance().shutdown();
To create other thread pools, simply define a worker thread and its constituent parts. The worker thread must define request_type, prepare_request, and thread_proc. The LPVOID parameter passed to thread_proc is always 0, and should not be used. The thread pool may be extended to provide context through this parameter. The code below defines an io::thread and an io::thread_pool.
// sample io worker thread
namespace io {
struct thread
{
typedef io::session request_type;
static void prepare_request(request_type*) throw();
static void thread_proc(LPVOID) throw();
}; // struct thread
struct thread_pool : core::thread_pool<io::thread> {};
} // namespace io
Users may access io::thread_pool with io::thread_pool::instance();.
About the Demo Program
The demo program does the following:
- Initializes the global::thread_pool instance.
- Instantiates three different types of work.
- Instantiates a chain tying the work together.
- Queues and processes the work.
- Shuts down the thread pool.
If you are a member of a team, you can quickly divide and distribute the work to the team to implement as work units. Each work unit can be tested independently and integrated as a final product. Each person has a sandbox to play in.
Thread pools are a fantastic tool for writing large, scalable systems quickly and safely without sacrificing performance.
Happy Coding!