

This article is intended to give an overview of how PCM audio is stored and processed on a PC. It also explains the structure of wave files and shows you how to work with them using code written in C++. But, the actual theory behind PCM, such as aliasing and so forth, is beyond the scope of this article. I may try to address those in a separate, future article.
In Brief, What Is PCM?
In the digital domain, PCM (Pulse Code Modulation) is the most straightforward mechanism to store audio. The analog audio is sampled in accordance with the Nyquest theorem and the individual samples are stored sequentially in binary format.
The wave file is the most common format for storing PCM data. But, before you dig into the internals of wave files, it would help to get some insights to the Interchange Format Files that form the basis for the wave file format.
Interchange Format Files (IFF)
It is a “Meta” file format developed by a company named Electronic Arts. The full name of this format is ElectronicArts Interchange File Format 1985 (EA IFF 85). IFF lays down a top-level protocol on what the structure of IFF compliant files should look like. It targets issues such as versioning, compatibility, portability, and so forth. It helps specify standardized file formats that aren’t tied to a particular product.
For the purpose of explaining wave files, it would surmise to say that the wave file format is based on the generic IFF format. If you are interested in digging deeper into IFF, here is a wonderful link:
http://www.dcs.ed.ac.uk/home/mxr/gfx/2d/IFF.txt.
The WAVE File Format
The WAVE File Format supports a variety of bit resolutions, sample rates, and channels of audio. I would say that this is the most popular format for storing PCM audio on the PC and has become synonymous with the term “raw digital audio.”
The WAVE file format is based on Microsoft’s version of the Electronic Arts Interchange File Format method for storing data. In keeping with the dictums of IFF, data in a Wave file is stored in many different “chunks.” So, if a vendor wants to store additional information in a Wave file, he just adds info to new chunks instead of trying to tweak the base file format or come up with his own proprietary file format. That is the primary goal of the IFF.
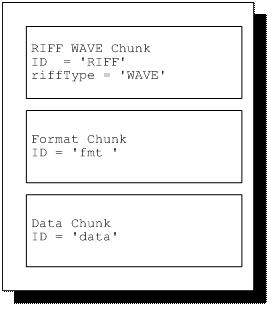
As mentioned earlier, a WAVE file is a collection of a number of different types of chunks. But, there are three chunks that are required to be present in a valid wave file:
- ‘RIFF’, ‘WAVE‘ chunk
- “fmt” chunk
- ‘data’ chunk
All other chunks are optional. The Riff wave chunk is the identifier chunk that tells us that this is a wave file. The “fmt” chunk contains important parameters describing the waveform, such as its sample rate, bits per sample, and so forth. The Data chunk contains the actual waveform data.
An application that uses a WAVE file must be able to read the three required chunks although it can ignore the optional chunks. But, all applications that perform a copy operation on wave files should copy all of the chunks in the WAVE.
The Riff chunk is always the first chunk. The fmt chunk should be present before the data chunk. Apart from this, there are no restrictions upon the order of the chunks within a WAVE file.
Here is an example of the layout for a minimal WAVE file. It consists of a single WAVE containing the three required chunks.
While interpreting WAVE files, the unit of measurement used is a “sample.” Literally, it is what it says. A sample represents data captured during a single sampling cycle. So, if you are sampling at 44 KHz, you will have 44 K samples. Each sample could be represented as 8 bits, 16 bits, 24 bits, or 32 bits. (There is no restriction on how many bits you use for a sample except that it has to be a multiple of 8.) To some extent, the more the number of bits in a sample, the better the quality of the audio.
One annoying detail to note is that 8-bit samples are represented as “unsigned” values whereas 16-bit and higher are represented by “signed” values. I don’t know why this discrepancy exists; that’s just the way it is.
The data bits for each sample should be left-justified and padded with 0s. For example, consider the case of a 10-bit sample (as samples must be multiples of 8, we need to represent it as 16 bits). The 10 bits should be left-justified so that they become bits 6 to 15 inclusive, and bits 0 to 5 should be set to zero.
As an example, here is a 10-bit sample with a value of 0100001111 left-justified as a 16-bit word.
The image kind of got blurred during conversion from BMP to a GIF, but I hope it is legible enough. The MSB ends in 15. That’s what I drew, but it kind of looks like a 16, doesnt it? Pardon me for that.

Given the fact that the WAVE format uses Intel’s little endian byte order, the LSB is stored first, as shown here:

The analogy I have provided is for mono audio, meaning that you have just one “channel.” When you deal with stereo audio, 3D audio, and so forth, you are in effect dealing with multiple channels, meaning you have multiple samples describing the audio in any given moment in time. For example, for stereo audio, at any given point in time you need to know what the audio signal was for the left channel as well as the right channel. So, you will have to read and write two samples at a time.
Say you sample at 44 KHz for stereo audio; then effectively, you will have 44 K * 2 samples. If you are using 16 bits per sample, then given the duration of audio, you can calculate the total size of the wave file as:
Size in bytes = sampling rate * number of channels * (bits per sample / 8) * duration in seconds
Number of samples per second = sampling rate * number of channels
When you are dealing with such multi-channel sounds, single sample points from each channel are interleaved. Instead of storing all of the sample points for the left channel first, and then storing all of the sample points for the right channel next, you “interleave” the two channels’ samples together. You would store the first sample of the left channel. Then, you would store the first sample of the right channel, and so on.