

By Alex Homer
"An Overview of XML Support in SQL Server 2005"
Ever since the mid 90’s, as XML has evolved to become the
optimum way to share, transport and persist data, developers have sought efficient
ways to store, manipulate and generally take advantage of its capabilities.
Increasingly fast and easy-to-use XML parsers have been developed, transport
protocols such as SOAP have been used to implement Web Services around XML, and
many applications, tools and programming libraries now include features to
import and export their data as XML.
However, the one area that has seen less development,
particularly in the Microsoft world, is the implementation of efficient and
robust technologies for persisting XML. XML is basically just text, and the
most common persistence format is as a disk file in some standard text-based
format such as ANSI, Unicode, etc. This is generally fine for single-user
applications, but does prompt some serious questions when used in a
server-based and/or multi-user environment.
This and the two subsequent articles look at how the latest
version of Microsoft’s enterprise-level database, SQL Server 2005, now
offers great support for and close integration with XML as a data persistence
format. This includes new ways to validate, store and query XML documents that
are stored within the database. SQL Server 2005 provides native support for XML
that can vastly improve application performance, while supporting robust and
safe multi-user access to the data contained within the XML documents.
The topics we’ll be covering in this article are:
- A brief overview of the way that SQL Server 2005 stores
XML documents and schemas - How SQL Server 2005 provides support for querying and
manipulating XML documents - A simple test application that allows you to experiment
with XQuery
In two subsequent articles, we’ll see some techniques for
improving the performance of applications that work with XML documents, as well
as some examples of the different ways you can use XQuery:
- Extracting data from xml columns, using parameter with
XQuery and combining XQuery and XSL-T - Updating the contents of xml columns, and using XQuery in a
managed code stored procedure
An Overview of XML Support in SQL Server 2005
SQL Server 2005 adds a raft of new features
to support XML data storage and manipulation. These features make it easier to
persist your XML documents within the database, while providing increased
performance over the traditional techniques. We’ll be comparing these
traditional techniques, and seeing how you can improve the performance of your
applications, in Parts 2 and 3. For the moment, however, we’ll briefly explore
the new features in SQL Server 2005. These include:
- A dedicated data type named xml that can be used to store XML
documents or fragments of XML - The ability to register XML schemas with SQL Server 2005,
and store schema information within the database - Automatic validation of XML documents when a schema is
present; and automatic shredding of the XML data to support efficient
querying and updating of the content - An implementation of a subset of the W3C XQuery language and
XML-DML to provide this querying and update facility - Support for hosting the .NET Common Language Runtime (CLR)
within SQL Server, which allows stored procedures that manipulate XML
documents to be written in managed code
You’ll see how all these features come into play throughout
these three articles, and how they open up new techniques for working with XML
documents and XML data.
XML Schemas and the W3C Infoset Model
In recent years, it’s become increasingly
obvious that the major uses of XML are as a way of storing both rowset (single table) and hierarchical (multiple-table) data, rather than
unstructured information such as newspaper articles. For example, a common use
of Web Services in .NET applications is to expose data that represents a DataSet in a format that allows discovery and transmission across HTTP
networks such as the Internet. The DataSet may contain a
single table, or multiple tables that are related through primary and foreign
keys, and the XML data can be used to completely reconstruct that DataSet on the client.
To specify the data type for an element or
an attribute in an XML document you use a schema. This indicates, for example, whether
a value such as "42"(which is stored as a text string within the XML) represents either
a character string or a numeric value. The client can then reconstruct the data
stored in the XML document so that it is accessible as the appropriate data
types. This is at the heart of the recent moves towards the XML Information
Set (Infoset) model,
which effectively considers an XML document as one or more typed rowsets.
For details of the W3C Infoset recommendation,
see http://www.w3.org/TR/xml-infoset/
This means that you must expose an XML
Schema (or the relevant schema information) for every XML document or fragment in
order to take advantage of the Infoset model and data-typing of the XML content.
SQL Server 2005 makes this easy by providing a schema repository that
you can use to store XML schemas, and it will automatically use the appropriate
schema to validate and store XML data.
The XML Schema Repository
Schemas are added to a database by
executing the CREATEXMLSCHEMACOLLECTION statement, for example:
CREATE XML SCHEMA COLLECTION MyNewSchemaCol
‘<xsd:schema xmlns="…">
… schema content …
</xsd:schema>’
You can add multiple schemas in one go by
concatenating them together, use the ALTERXMLSCHEMACOLLECTION statement to add or remove
individual schemas in a collection, and remove the collection using the DROPXMLSCHEMACOLLECTION statement. See the SQL Server help files for more details.
The name you assign to the collection
("MyNewSchemaCol" in the code above) is used in the ALTER and DROP statements, and is displayed in SQL Server Management Studio.
However, you should include a targetNamespace attribute in the opening <schema> element
to identify each schema in the collection, for example:
<xs:schema xmlns_xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://myns/mydemoschema">
…
</schema>
Then you link your XML documents to the
appropriate schema by specifying this namespace:
<?xml version="1.0"
encoding="utf-8"?>
<root xmlns="http://myns/mydemoschema">
…
</root>
You can use SQL Server Management Studio to
view and manage schemas and schema collections. For example, Figure 1 shows the
schema collections in the AdventureWorks sample database that you
can download and install in SQL Server 2005.
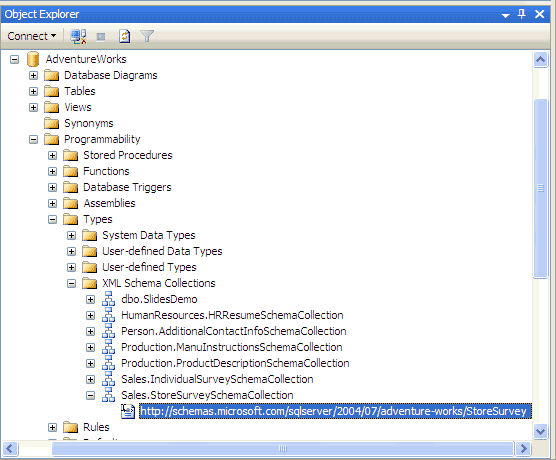
Figure 1 – The schema
collections in the AdventureWorks sample database
The New xml Native Data Type
SQL Server 2005 supports a new native data type named xml that you use
in exactly the same way as any other built-in data type. You can use it to
define a column type for a table, as a parameter or variable in a stored
procedure, and anywhere else you would use built-in types such as nvarchar, int, etc. The xml type can store
either a complete XML document, or a fragment of XML, as long as it is
well-formed (you cannot use an xml type to store XML that is not well-formed).
Typed and Un-typed xml Columns
When you provide a schema for the XML documents you will
store, you can create a typedxml column in a table. You specify the
name of the schema collection that contains the schema you want to apply to
that column, for example:
CREATE TABLE MyTable(MyKey int, MyXml xml(MyNewSchemaCol))
Now the content of the XML document you
insert into that column will be shredded automatically into its individual data
items, and SQL Server will store these internally in the most efficient and
compact way possible. When you query the column, SQL Server automatically
reconstructs the XML document into its original form. Note, however, that this
will not include things like comments that are not part of the original data
content of the document. What you get back is effectively a serialized rowset
that represents the data you originally stored there.
It’s also possible to store your XML
documents without specifying a schema, in which case you create an un-typedxml column. In this case, the XML is stored as a simple character
string, because SQL Server has no way of knowing the data type of each element
and attribute. This is less efficient, but does maintain the complete original
content of the XML document (such as comments, etc.). But remember that, even
with an un-typed column, the XML you insert must be well-formed.
To create an un-typed column, you simply
omit the schema collection name when you create the table:
CREATE TABLE MyTable(MyKey int, MyXml xml)
Figure 2 shows SQL Server Management Studio displaying the
structure of the Sales.Store table in the AdventureWorks sample database. You can see the xml-typed column named Demographics in the left-hand tree view,
and a query that extracts the rows from this table in the right-hand query
window. The results of running this query are shown in the grid below this, and
we’ve super-imposed on this the view of the XML document you get when you click
on the contents of one of the columns in the grid.
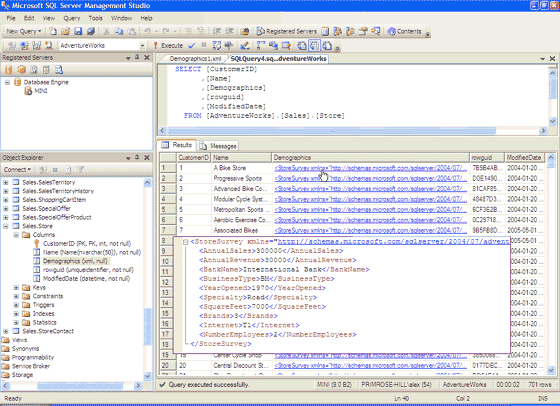
Figure 2 – The xml column in the Sales.Store table, showing one of the XML documents
it contains
Inserting and Selecting on an xml Column
Once you have created your table, you
insert an XML document into an xml column in the same
way as you would for any other built-in data type. You can insert it as a
string value, or use the CASTor CONVERT functions to
specifically convert it to an xml type:
INSERT INTO MyTable(MyKey, MyXml)
VALUES (1, ‘xml-document-string’)
INSERT INTO MyTable(MyKey, MyXml)
VALUES (1, CAST(‘xml-document-string’) AS
xml))
INSERT INTO MyTable(MyKey, MyXml)
VALUES (1, CONVERT(xml, ‘xml-document-string’))
When extracting an XML document from an xml column you can convert it to a char, varchar, ncharor nvarchartype if you want to specify the character format:
SELECT CONVERT(nvarchar(500), MyXmlDoc, ‘utf-8’)
FROM MyTable WHERE … etc. …
Querying and Manipulating XML in SQL Server 2005
The previous section of this article has
described the techniques for creating tables that contain an xml column, and how you can insert and extract XML documents from such
a table. However, these assume that you actually want to access the complete
document. As you’ll see later, this often isn’t the best way to work with XML –
especially if you only need to access or update specific parts of the XML
document.
SQL Server 2005 supports two new XML
manipulation techniques that can provide better performance and reduce the
application-level code you have to write. These new techniques are XQuery and the support for XML-DML in the xml data type, and we’ll
briefly look at both of them next.
XQuery Support in SQL Server 2005
For a long time, XML and relational data
have been considered to be two different (yet complimentary) approaches to
working with data. However, as you saw earlier, the XML Infoset model and the
use of XML Schemas has narrowed that divide so that developers increasingly
need to work with their data in both formats, and be able to switch between
them easily.
The least intuitive aspect of this is that
the developer needs to master the techniques for querying XML documents, and
often this involves transforming them into the required format. Until quite
recently, this meant either performing complex processing of the XML as a
character string, or using an XSL-T style sheet. XSL-T is a very powerful
technology, but is not particularly intuitive or easy to use.
In response to this, the W3C has committed
to producing a recommendation for a new query language called XML Query,
or XQuery as it is more usually known. XQuery combines a syntax that is
familiar to developers used to working with relational data with the power of
the XPath language that is used to select individual sections or
collections of elements from an XML document.
We don’t have room here to provide a complete
tutorial for XQuery, but there are plenty of places you can go to read more
about it. These include the W3C Web site (http://www.w3.org/XML/Query),
which contains a section named "Other Pointers" providing links to
many other useful resources.
XQuery allows you to select individual
values from an XML document simply by specifying an XPath that identifies the
elements or attributes you want, for example:
doc("myxmlfile.xml")/root/product[@id="304"]/name
This code calls the built-in XQuery doc function to query a document named myxmlfile.xml, and
return the name element that is a child of the product element where that product element contains an attribute
named id that has the value "304".
The result would be something like:
<name>Large
Flange Compressor</name>
Alternatively, you can use an XQuery FLWOR statement to
build up an XML document that contains values from the source document. FLWOR
is an acronym that describes the sections of the XQuery statement you can use –
the basic syntax is:
for [$variable] in [sequence-or-context]
let [$variable] := [sequence-or-context]
where [expression]
order by [expression]
return [literal-and-nodes]
For example, you can create an XML document
that has a root element named myproductlist, and
contains a list of product descriptions ordered by product name where the value
of the id attribute is greater than 10, using this kind of syntax:
<myproductlist>
{
for $p in doc("products.xml")//product
let $d := $p/description
where data($p/@id) > "10"
order by $p/name[0]
return $d
}
</myproductlist>
The result would be of the form:
<myproductlist>
<description>Reverse
flange compressor for big things</description>
<description>Extrapolating
geek extractor for Windows XP</description>
<description>Cross-compiling
actuarial extender with flaps</description>
</myproductlist>
SQL Server 2005 supports a subset of the
XQuery language, so you can use these kinds of queries to extract data from XML
documents stored in both typed and un-typed xml columns. However,
note that SQL Server 2005 does not support the let statement – in
almost all cases you can create an equivalent query without requiring this.
XQuery also implements a large selection of
built-in functions, including the data function used in
the example above (this function extracts the contents of an element – without
it you get back the complete element including the opening and closing element
tags). SQL Server 2005 implements the most common functions, and in general you
will find that you can accomplish all the tasks you need with the subset that
are available.
Note that SQL Server 2005 does not implement
the doc function, as the XML
input comes from a column in the database rather than from a disk file. You’ll
see in the next section how we access an XML document within an XQuery.
XML Methods and XML-DML Support in SQL Server 2005
The second new technology supported by SQL
Server 2005 is the XML Data Manipulation Language (XML-DML). The
new xml data type in SQL Server 2005 is, of course, an object in its own
right (a class that implements the required behaviour and persistence for an
XML document). And, like any other object, it exposes methods that you can use
to manipulate the data it contains. These methods include:
- The query method, which returns a fragment of un-typed XML
- The value method, which returns a single value from the XML and exposes it as a
standard (non-xml) SQL data type - The exist method, which can be used to test whether a specific node/value exists in
the XML data - The modify method, which executes an XML Data Modification Language (XML-DML)
statement - The nodes function, which returns a single-column rowset of nodes from the XML
The query, value and exist methods are useful if you just need to access an XML document to
get specific values from it or check if it contains a specific value, without
having to extract the whole document. The modify method is useful
when you want to update the XML content by executing an XML-DML statement. Again,
you can do this without having to extract the whole document.
Using the query Method
As an example, this is a SQL statement that
queries the XML in an un-typed column named MyXml in a table named MyTable, and returns the
matching name element:
SELECT MyXml.query(‘/root/product[@id="304"]/name’)
FROM MyTable
The result would be something like:
<name>Large
Flange Compressor</name>
As you can see, there is no need to use the
XQuery doc function. To get just the value of the matching element, you can
use the data function:
SELECT MyXml.query(‘data(/root/product[@id="304"]/name)’)
FROM MyTable
In this case, the result would be just:
Large
Flange Compressor
If the xml column you are
querying against is a typed column (in other words, there is a schema
registered for this column), you must specify the namespace for the schema in
your query. The easiest way is to assign the namespace to a prefix, and use
this prefix with each element in the query. For example:
SELECT MyXml.query(‘
declare namespace s="http://myns/mydemoschema";
/s:root/s:product[@s:id="304"]/s:name’)
FROM MyTable
You can also use the query method to execute a FLWOR XQuery. Based on the example we looked at
earlier, we can build an XML document that contains a list of product names from
a table containing a column named ProductXMLusing this
query:
SELECT ProductXML.query(‘
<myproductlist>
{
for $p in //product
where data($p/@id) > 10
order by $p/name[1]
return $p/description
}
</myproductlist>’)
FROM ProductList WHERE ProductGroup = 3
This assumes that each row in the ProductList table is an XML document containing a list of products in a
specific category (ProductGroup is the column containing the category number). It will returns an
XML document such as:
<myproductlist>
<description>Reverse flange compressor for big things</description>
<description>Extrapolating geek extractor for Windows
XP</description>
<description>Cross-compiling actuarial extender with
flaps</description>
</myproductlist>
Using the value Method
The value method works much
like the query method, except that it takes a second parameter that is the name of
one of the SQL Server built-in data types. The value is returned as an instance
of that type. The other point to note is that the XPath you specify must return
a single node, so you should specify the node index (when using the query method, the XPath can select more than one node and will return an
XML fragment or list of these matching nodes). For example:
SELECT MyXml.value(‘(/root/product[@id="304"]/name)[1]’,
‘nvarchar(30)’)
FROM MyTable
Remember that you must declare the
namespace of the document if the source column is a typed xml column.
Using the exist Method
The exist method takes an
XPath expression that selects a single node within the XML document, and
returns either True (bit value 1) if the node exists or False (bit value 0) if it does not. If the source column
is a typed xml column (in which case you must declare the namespace in your
query), and the element contains null, the method returns NULL instead. So the XQuery:
SELECT MyXml.exist(‘(/root/product[@id="304"])[1]’
FROM MyTable
will return True if there is a
product with the id value "304" (a product element with the attribute id="304"), or False if not. You can also use the exist method in the WHERE clause of a SQL statement:
SELECT column1, column2, column3 FROM MyTable
WHERE MyXml.exist(‘(/root/product[@id="304"])[1]’)
= 1
Using the modify Method
While the query, value and exist methods are extremely useful, the one that really puts the icing on
the cake, as far as manipulating XML in SQL Server 2005 is concerned, is the modify method. This method allows you to change the contents of the XML
document stored in an xml column without having to retrieve it,
modify it, and then put is back afterwards. The general syntax of the modify method is:
xml-column.modify(‘insert-query‘
| ‘delete-query‘ | ‘replace-query‘)
As you can see, there are three types of
"query" that you can use within the modify method. Each of
these is, in fact, an XML-DML statement that is executed against the XML
document in that column. This means that you can insert new nodes or fragments
into an XML document, delete existing modes or fragments, or replace the value or
content of existing nodes with new values or XML fragments.
Remember that – in a typed xml column – the resulting XML document, after executing the XML-DML
statement, must conform to the schema for the column. If not, the update is
abandoned and an error is raised.
As an example, this code deletes the productnode that has an attribute id="304" from
the document:
UPDATE MyTable SET MyXml.modify(‘delete /root/product[@id="304"]’)
This code deletes all the description elements from the document:
UPDATE MyTable SET MyXml.modify(‘delete /root/product/description’)
You could also achieve the same result by
using an XPath that just selects all the descendant description nodes directly:
UPDATE MyTable SET MyXml.modify(‘delete //description’)
To insert a new node or fragment of XML,
you use an insert statement. The syntax for this is:
xml-column.modify(‘insert new-content
{as first | as last}
into | before | after
xpath-expression‘)
where new-content is the XML you want to insert, and xpath-expression is
an XPath that selects a single existing node within the document. You separate
these two expressions with a combination of keywords that indicate where in
relation to the target node specified by xpath-expression you want to insert
the new content. You can insert it as a child of the target node using
the into keyword, in which case you must also specify whether it should be the first or
the last node within the child nodes collection of the target element:
MyXml.modify(‘insert <newelement>New
element content</newelement>
as first into (/root/product[@id="304"])[1]’)
If you want to insert the new content as a sibling of the existing node (rather than into the child nodes collection of the target
node), you use the before or after keyword instead. This code inserts the new XML fragment into the
target document so that it comes before the product node that has
the attribute id="304":
MyXml.modify(‘insert <product
id="278">…new element content…</product>
before (/root/product[@id="304"])[1]’)
Finally, you can use the replace method to update a value in an existing node. However, note that
the replace method can only be used in a typedxml column. Using it with an un-typed xml column fails because
the method requires that the data types of the new and existing values are of
the same scalar types. The general syntax of this method is:
xml-column.modify(‘replace
value of xpath-expression with new-value‘)
where xpath-expression specifies a single
node within the document, and new-value is the value or XML fragment you want to
replace it with. As an example, this code changes the value of the name child element
within the product element that has the attribute id="304":
MyXml.modify(‘replace value of (/root/product[@id="304"]/name)[1]
with "New reverse flange
extractor"’)
Of course, as with all the other methods,
you must specify the namespace when querying against a typedxml column. For example, the previous query – if executed against a
typed column that uses a schema with targetNamespace="http://myns/mydemoschema" – would need to be changed to:
MyXml.modify(‘declare namespace
s="http://myns/mydemoschema";
replace value of (/s:root/s:product[@s:id="304"]/s:name)[1]
with xs:string("New
reverse flange extractor")’)
Notice how the new content is cast to the
correct type to match the element type specified in the schema. This assumes
that the schema uses the namespace prefix "xs" to refer to the
data types it defines. The cast to the type xs:string therefore
makes sure that the new value matches the type defined in the schema. Alternatively,
you can use the syntax:
…
with "New reverse flange
extractor" cast as xs:string ?
Notice the question mark at the end of the
statement. This is required because, if there is a cast error, XQuery rules
insist that the statement returns an empty node sequence.
Using the nodes Method
The previous sections have looked at the query, value, exist and modify methods that are exposed by the new xml data type in SQL
Server 2005. The final method that is available is the nodes method. This is useful when extracting data from an XML document,
and can be used to create new tables based on the contents of the XML document.
For example, if you think of an XML
document that describes a list of products as though it were a rowset, the nodes method can be used to create a new table where each product becomes
a row in that table. This code creates such a table, which will then contain
one column named ProductName. There will be a row for each product element in the original
document, and the ProductName column will contain an XML document that has the product element as its root and includes all of the child nodes for the
product element that were in the original XML document.
MyXml.nodes(‘/root/product/name’) as NewTable(ProductName)
In other words, each row will contain an
XML document such as:
<product
id="304"><name>…</name><description>…</description></product>
The nodes method is commonly
used in conjunctions with the CROSSAPPLY statement to
create a rowset that is used as the input for another query. For example, this
code creates a temporary rowset named NewTablecontaining a
column named ProductDetails, which holds all the product elements, and then returns them using
the XQuery ‘.’ (the current node) in a call to the query method.
SELECT NewTable.NewColumn.query(‘.’) AS ProductName
FROM ProductList CROSS APPLY ProductXML.nodes(‘//product’)
AS NewTable(ProductDetails)
WHERE ProductGroup = 3
This gives a result such as:
<product
id="304"><name>…</name><description>…</description></product>
<product
id="732"><name>…</name><description>…</description></product>
<product
id="882"><name>…</name><description>…</description></product>
Passing Parameters to an XQuery
One issue that we haven’t considered so far
is how you can pass variables to an XQuery that are used within the XPath that
selects parts of the XML content. All the previous examples have used fixed
values in the queries, for example the XPath "/root/product[@id="304"]/name".
In any real-world application, you’ll need to pass variables into your data
access code routines, rather than using a fixed value. There are, however,
several ways you can achieve this. One way is to limit the rows that are
returned by using a parameter as part of the WHERE clause, for example:
SELECT ProductXML.query(‘//description’) FROM
ProductList
WHERE ProductXML.value(‘(//product/@id)[1]’,
‘int’) = @product_id
You just need to add a parameter named @product_id to the command you use to execute the query, and the resulting
rowset will only include the description element from
the product that has the matching value for its id attribute. However,
if you need to reference a parameter value within the XQuery itself, this
approach is not of any use. Instead, you can take advantage of two extensions
to the XQuery syntax supported by SQL Server 2005 by binding to relational data
within your XQuery – as described next.
Binding to Relational Data in an XQuery
SQL Server 2005 adds two new functions to
XQuery that allow you to reference values normally only available in standard
Transact-SQL (T-SQL) statement from within an XQuery query. These two
extensions are:
- The sql:variable function, which allows you to reference a variable or parameter that is
declared within the SQL statement or stored procedure from within an
XQuery - The sql:column function, which allows you to reference another (non-xml) column from within an XQuery
As an example of their use, we could write
an XQuery that selects description elements for the product that
has an id attribute value equal to a parameter named @product_id like
this:
— note that this will probably not produce
the results you expect
SELECT ProductXML.query(‘/root/product[id=sql:variable("@product_id")]/description’)
FROM ProductList
The value of the @product_id parameter is referenced using the sql:variable function, and evaluates to
the value of the parameter when the XQuery is parsed and executed. However, as you can see from the comment in the text, this will
probably not give you the results you expect. It will return a row for
every row in the original table, with a NULL value for rows that
don’t match on the product ID.
Instead, you should use a WHERE clause to limit the rows that are returned, using the XML-DML exist method to match the product ID value to the value of the parameter.
This code will return only the matching row from the table:
SELECT ProductXML.query(‘//description’) FROM
ProductList
WHERE ProductXML.exist(‘//product[./@id = sql:variable("@product_id")]’)
= 1
Notice that the sql:variable function is used in the exist method so that it
will return True (bit value 1) only when there is a product element with an id attribute that has the same value as the parameter named @product_id.
Note that you must ensure the data types of
the node value and the parameter are correctly matched in the XQuery when you
perform a comparison of the node value in the XML with the parameter value. For
example, if the parameter you pass to the query is an numeric type, you must
use the XQuery number function to
convert the node value to a numeric type. So the XPath expression for the
previous example would look like this:
‘//product[number(./@id[1])
= sql:variable("@product_id")]’
In this case, the value of the id attribute is converted to a numeric type before comparing it to the @product_id parameter value.
And, because the number function demands a single node as its source, we have to specify the index [1] as well.
The sql:column function can be used in the same way. Instead of providing the value of a
parameter, it takes the value from the specified column in the current row in
the table. For example, this code creates an XML fragment based on a root
element named result,
which contains the product ID as stored in the column named ProductRowID in
this row of the table; plus the name and description extracted from the XML
document in the ProductXML column:
SELECT ProductXML.query(‘
<result>
<product_id>{ sql:column("ProductRowID")
}</product_id>
<product_name>{ data(//name) }</product_name>
<product_description>{ data(//description)
}</product_description>
</result>
‘)
FROM ProductList WHERE ProductRowID = 25
For a more detailed discussion of the xml data type methods and XML-DML statements, search the SQL Server
2005 help files for "xml data type methods".
There are also several useful articles on the MSDN Web site, for example: http://msdn.microsoft.com/library/en-us/dnsql90/html/sql25xmlbp.asp and http://msdn.microsoft.com/library/en-us/dnsql90/html/sql2k5xml.asp.
Playing with XQuery in SQL Server
The syntax for XQuery can, as you’ve seen
in this article, become somewhat complex. To allow you to experiment more
freely with XQuery, we provide a simple "test" application that
executes an XQuery against SQL Server 2005. Figure 3 shows the application in
use, and you can see that there is a selection of queries provided that you can
run and modify – or you can simply type in your own XQuery and execute it. The
queries we provide demonstrate most of the functions and methods described in
this article.
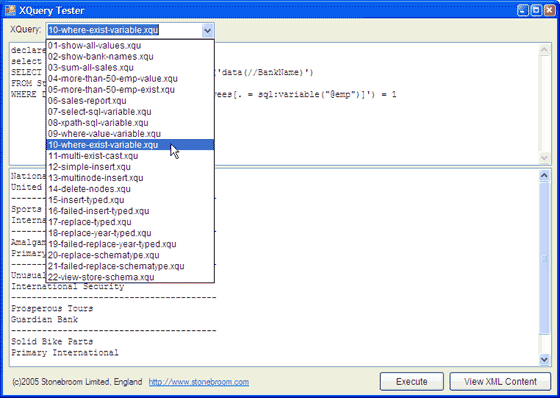
Figure 3 – The
XQuery Tester application that is available to download and use to experiment
with XQuery
All the samples for this and the following two
articles can be downloaded from http://www.daveandal.net/articles/sql2005-xquery/.
The samples include a ~readme.txt setup file, and a script to create the tables used by the examples.
Summary
Over the last few years, XML has moved from being a way to
mark up documents so that they can be parsed by special applications, into a
standard way to transport, persist and manipulate rowset data. The development
of the XML Schema and XML Infoset standards means that XML is now a
fully-fledged and widely used data format, and is increasing supported in
modern applications, tools and programming libraries.
The one issue with XML has always been storage. Unlike
relational data, where established and proven technologies exist to manage
storage, querying and updating, XML has long been considered to be mainly a
disk-based or stream-based format. But databases such as Oracle, and now SQL
Server 2005, provide great ways of managing XML.
In SQL Server 2005, the topic of this article, there is a
schema repository, a new XML column type, support for a subset of the XQuery
language, and an implementation of XML-DML. In combination, these features
allow developers to work with XML in similar ways to relational data.
This article, the first of three, has given you an overview
of these new features in SQL Server 2005. In the following articles, we move on
to look at how you can improve the performance of your applications, and
provide a more robust environment for working with XML data, using the
techniques and features of SQL Server 2005 described here.