

Are you a DataSet person or more of a business object person? What an awful choice to make! On the DataSet side, you lose the intelligence that you can stuff into your business objects. On the business object side, you lose searching, sorting, and other basic abilities to work with your data that the .NET Framework provides in the System.Data namespace.
Fortunately, Microsoft will soon offer an alternative: LINQ (Language Integrated Query), and specifically for database-related operations, DLINQ. DLINQ is the component of the LINQ project that provides a run-time infrastructure for managing relational data as objects—without giving up the ability to query.
Ostensibly, DLINQ provides this solution by giving you the representation of a strongly typed database. In other words, if you had a customers table, you could create a class very similar to the following:
[Table(Name="Customers")]
public class Customer
{
[Column(Id=true)]
public string CustomerID;
[Column]
public string City;
}
This class, with some other work, then would allow you to write queries in your .NET code as follows:
var q =
from c in db.Customers
where c.City == "London"
select c;
So, you could use a relational, tabular representation of data in the database as objects that are strongly typed and checked at compile time in your .NET code. This allows you to both query your objects and stuff intelligence in them via mechanisms such as inheritance or partial classes. But isn’t that what LINQ provides? Then, what does DLINQ add to the puzzle, besides simple query and persistence?
On the surface, DLINQ’s functions sound quite straightforward: “represent relational data as objects,” and “provide a mechanism to do the translation.” But, a closer look quickly reveals various other hairy monsters in the sewer that need to be tamed.
For instance, the data that DLINQ queries upon does not have to worry about concurrency issues or transactional support. It doesn’t have to worry about versioning or being disconnected from a huge data cache—your database. It also doesn’t have to worry about preserving object identities. An object, when queried, always returns a copy of the data, but what if your object (say, “Customers”) had been modified since the last time you read it? Objects that rely on database objects aren’t instantaneously updated by the underlying database, unlike regular business objects, of which there is only one in-memory instance.
Also, how should your DLINQ queries be written so they execute efficient queries on the database and participate as good connection-pooling citizens in your architecture? Can you override the default behaviors?
This article attempts to answer a few of these questions. But first, how does DLINQ work?
The DataContext Class
At the heart of DLINQ is the DataContext class. Suppose you have a database that is created by the following T-SQL script:
Create Database Test
Go
Use Test
Go
Create Table Entity
(
EntityID INT IDENTITY PRIMARY KEY,
EntityName Varchar(100) NOT NULL
)
Go
Create Table EntityDetail
(
EntityDetailID INT IDENTITY PRIMARY KEY,
EntityID INT REFERENCES Entity(EntityID),
EntityDetailName Varchar(100) NOT NULL
)
Go
The following figure represents the two resulting tables.
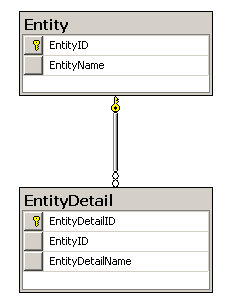
If you insert some sample data using the following script:
BEGIN
DECLARE @LASTID INT
Insert Into Entity (EntityName) Values ('TestEntity')
Select @LastID = SCOPE_IDENTITY()
Insert Into EntityDetail(EntityID, EntityDetailName)
Values (@LastID, 'Detail 1') ;
Insert Into EntityDetail(EntityID, EntityDetailName)
Values (@LastID, 'Detail 2') ;
END
Go
You could easily create a not-strongly-typed DataContext and use it to query the Entity Table as follows:
DataContext db = new DataContext(connectionString);
Table<Entity> Entities = db.GetTable<Entity>();
var q =
from e in Entities
where e.EntityName == "TestEntity"
select e;
foreach (var entity in q)
Console.WriteLine("EntityID = " + entity.EntityID);
For this code to work, it assumes a class called Entity already has been set up with the following structure:
[Table]
public class Entity
{
[Column(Id=true)]
public int EntityID;
[Column]
public string EntityName;
}
But wouldn’t it be a lot better to have a strongly typed DataContext instead? This would allow compile-time checking, and enable you to write more intuitive code like this:
TestDataContext db = new TestDataContext(connectionString);
var q =
from e in db.Entities
where e.EntityName == "TestEntity"
select e;
You could use a tool such as SqlMetal to do this, but it is important to understand the structure and layout of a strongly typed DataContext. Much like a strongly typed DataSet, at the heart of a strongly typed DataContext is a class that inherits from DataContext:
public partial class TestDataContext : DataContext
{
public Table<Entity> Entity;
public Table<EntityDetail> EntityDetail ;
public TestDataContext(string connStr) : base(connStr) {}
}
As you can see, you now need to create two classes that represent the “Entity” and “EntityDetail” tables. Let’s start with Entity:
[Table(Name="Entity")]
public class Entity
{
...
}
The “Name” property is really not necessary, because in this case it matches the database. However, by specifying it anyway, you can explicitly map to a table. You then could put the name in a resource/satellite assembly, so that if the structure changes, you can update all names in one place.