

By Anthony Brown
This article was excerpted from the book Reactive Applications with Akka.NET.
The Internet was initially started as a research project for the United States government. It then blossomed into the phenomenon it is today. The graph below shows the growth of the number of users of the Internet over the past 25 years. With this growth comes a number of associated difficulties.
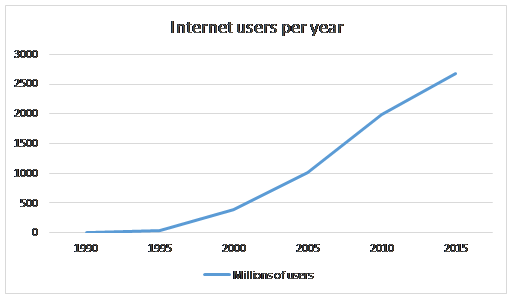
Figure 1: The increase in number of Internet users over the past 25 years
With technology becoming so commonplace, users are getting impatient when tasks take too long. For developers, this means that the traditional methods of solving problems are no longer applicable and we need new solutions for handling an increased set of wide requirements.
Note that your applications are potentially accessible by all of these users. This graph merely shows the number of users who have access to the Internet; the number of devices through which they can access the Internet may be significantly higher. Each of these users could have a desktop computer, a laptop and a smartphone, all of which are connected to the Internet and could potentially access your application.
As more people look to make their lives easier through the use of smart appliances thanks to the Internet of Things, this is likely to further increase the burden of potential traffic on applications. Some analysts have predicted that there is the potential for up to 30 billion devices, all of which are capable of accessing the Internet.
Any applications we build will need to be able to stand up to this amount of traffic. The traditional architectures from ten years ago simply won’t be able to cope as we seek to create applications that can operate on a scale high enough to be responsive to the end user.
Application requirements extend further than this though. Users want any applications they use to stay responsive in the face of failure. Whenever users browse to your website or service, they don’t want to experience error messages informing them that it’s broken. They want some meaningful replacement instead. Not only that, but the application should stay responsive in the face of these failures. If, for example, a database is unreachable, the user doesn’t want to spend long periods of time waiting whilst your application attempts to contact the unreachable database. In this situation, the user wants some replacement data to be quickly provided, whether this is data taken from a cache or elsewhere.
Ultimately for users, the key requirement is that any application they use remains usable regardless of what is happening behind the scenes. The applications they use should continue to be responsive in the face of system failure or when they’re under a varying load from users.
Requirements for businesses
The past 50 years has brought significant advances in the hardware available for businesses to use. The microprocessor revolution has seen vast increases in performance of the brains of a modern computer. The Intel 4004 was the first microcontroller ever developed and was equipped with a 740kHZ clock and 640 bytes of RAM. Since then, processors have developed at an incredible rate. Robert Moore of Intel predicted that every 18 months the number of transistors in a chip would double whilst the price would decrease by half (known as Moore’s Law).
Modern processors now hold billions of transistors compared to the mere 2,300 in the original Intel 4004. The past 10 years has seen a certain amount of stagnation, particularly in the area of processor speed. Few processors have chosen to go beyond the 3GHz mark and many have chosen to reduce clock speed in an effort to save on battery. The extra transistors available on these chips have been used to provide more independent cores, each of which is able to act as an extra processor. For developers looking to create more powerful applications, it’s imperative that they make use of the extra cores available to them on these processors.
The rise of the microcontroller has meant increases in the demand for other technologies and the ability to connect computers has also seen significant developments. Original researchers at MIT envisioned vast networks of interconnected computers, all of which are capable of sharing data and programs, allowing users access from anywhere in the world.
This growth has continued and has led into new areas of computing problems, most notably distributed systems. Distributed systems saw a significant paradigm shift from systems of the past. Previously, systems were built with a large mainframe as the core system that ran the application. Mainframes were typically large and expensive, meaning they were out of the reach of many organisations.
Distributed computing—essentially the combination of any number of machines, whether they’re mainframes, microcomputers or even personal computers made levels of computation available to anyone. This opens up increased levels of compute to more organisations as it allows them to start small and then work towards scaling up their architecture.
In recent years, distributed computing has seen even more increases in popularity, thanks in part to the cloud. The cloud has made distributed computing a more accessible goal for many developers. The cloud solves the economic problems related to distributed computing. Platforms such as Microsoft’s Azure and Amazon’s AWS allow developers to effectively hire computing power by only paying for what they use, in some cases rounded to the nearest minute of usage.
These advances have come at a time where organisations are competing for users in an increasingly competitive marketplace. Organizations can use the sheer amount of data that is being collected to gain deeper insights into customer behavior, thus giving them ways to improve their business. We’re turning into a society that truly values data. However, we’re creating so much of it that the only way to process it all effectively is across clusters of machines.
Building systems capable of meeting these new business requirements is far from easy. We require systems that are able to fully utilise all of the processing power at their disposal whilst also being able to expand onto multiple machines. We need systems capable of handling not only the increased amount of Internet users but also the increased amount of data all of those users are creating. The cloud movement has no intention of slowing so we need applications capable of operating in a cloud-first world.
Reactive systems aim to solve some of these problems by making it easier for developers to write applications that meet these new requirements. Toolkits like Akka.Net aim to take away the difficulties in creating these systems and working towards reactive applications by default.
The reactive methodology
Reactive application development is a significant paradigm shift and so it can be difficult to understand the approach one might take in dealing with architecting a system using these principles. However, a number of organisations operating in different domains found that they were all creating similar styles of applications doing similar kinds of work. In many instances, the patterns for building such applications were all the same. The applications were all intended to operate at the same standard regardless of exactly what was happening in the environment surrounding them. In response to this, these organisations started working towards a common language which would encapsulate the key principles of reactive systems. These principles then formed the basis of the reactive manifesto.
The principles of the reactive manifesto are shown in Figure 2. There is a significant reliance and connectedness between all of the elements. It isn’t that these are the only components required to create a reactive application; it’s simply that these tend to be the defining traits of a reactive application.
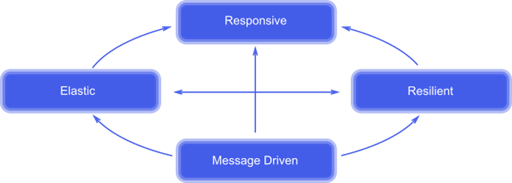
Figure 2: The key traits of a reactive application. Taken from the Reactive Manifesto (reactivemanifesto.org)
Responsive
The word responsive is a vague opening to the reactive manifesto but it encapsulates a number of other properties. It’s important to understand what is meant when we say an application should be reactive. The ultimate aim should be for the system to respond to the user’s request as quickly as possible. This ensures that the user is not spending significant amounts of time idly waiting for operations to complete. Responsive extends further than this though, in that an application should remain responsive regardless of the context under which it is running.
Elastic
In order for an application to be responsive, it needs to be able to react to an increased spike in usage. In the event that the usage of the application doubles, then the response time of the application shouldn’t also double. The easiest way to manage this is to create a system that allows for easy scalability to react to this increased pressure, by creating applications that can turn the number of instances of a service up and down in the event of an increased load. This allows applications to easily increase the available processing power.
An example of this is the case of E-commerce applications. An increased spike in usage means more people want to give the company money. In this case, a user wants the application to be responsive.
Resilient
For an application to be usable, it must withstand anything it is subjected to. Whilst this includes problems induced by users due to an increased load, it also includes problems generated from within the application. Errors are a common aspect of almost all applications, especially now thanks to the sheer number of data sources that are being combined to create more powerful applications.
However, there’s always the possibility that any of these external services could fail and so it’s important to consider what happens when an application does encounter an error. We need to create applications that are resilient, or resistant to sources of failure. Many applications consider resiliency as an afterthought and focus solely on a blue sky scenario. However, there are a lot of scenarios that can cause failure. You should consider how systems cope in the event of security problems, such as a lack of authorisation. As users integrate their lives with more and more services, we, as developers, need to be able to build applications capable of handling failure in third-party systems.
In the case of failure, an entire system shouldn’t struggle to cope, or, even worse, fail. Ideally, we want to be able to isolate failures down to the smallest possible unit and encapsulate them. This ensures that an application is still able to stand in the face of adversity. We don’t want to force the internal details of a failure onto users. Instead, we want to provide them with some details that are meaningful to them. We want to be able to automatically solve issues and allow applications to self-heal.
Scalability and resiliency share a strong connection; when an application is built with scalability in mind, it will be able to handle failures. If an application is built with resilience in mind, then it will be able to handle an increased load.
Message Passing Architecture
When we develop applications, we typically use a procedure call in order to retrieve some data or modify some state from a method or function. This allows us to asynchronously perform an operation with a request and response model of communication. A message-passing-based architecture is a form of asynchronous communication where data is queued up for a worker to process at a later stage in a fire-and-forget manner.
By choosing a message-passing architecture, we get a number of valuable building blocks with which we can create applications that are resilient, scalable and responsive. Message passing lets us isolate components. Once we have isolation, it’s possible to deploy the different tasks we’re likely to perform in the most ideal location, depending upon factors such as CPU, memory or the risk of failure.
Isolation is a key component for resilience. In the event that a single component fails, the rest of the system won’t fail with it. It also allows the failing component the chance to self heal over time by either backing off from a dependent service causing issues or restarting in an effort to reset its state.
Another bonus to message passing is location transparency, which doesn’t depend upon knowing an exact location. When we send a message to an address, the framework then deals with the intricacies of routing the message to the physical location of the service within the cluster, whether that service is located on the same machine or on a server in a completely different data center. This allows the framework to dynamically reconfigure the location of a running task without needing to alert the application to this change, allowing for easier scaling. Given a system failure, it’s entirely feasible for the framework to redeploy a service into a new location.
The routes to reactive
The problems relating to staying responsive vary depending on the circumstance. The reactive manifesto proposes solutions that relate to a variety of different architectures and situations. The principles behind the reactive manifesto are simply common traits of applications that ultimately remain responsive for the user under any number of conditions. These are then backed by the loosely coupled nature of the message-driven architecture. However, there is more than one way to pass messages through a system. The two methods—event-driven concurrency and actor-based concurrency—share the common ground of message passing, but the principles diverge and the use cases of the two techniques split.
Akka.Net—Actor based concurrency
One way of handling message passing is through the use of actor-based concurrency. Akka.Net is an implementation of the actor model, a means of modeling systems by splitting them into independent actors. An actor within the actor-based model encapsulates three key concepts: storage, behavior and communication.
Storage
Actors are able to store some data within the confines of the actor boundary. No data within the actor can be accessed by anything outside of the actor. This is one of the key components that allows applications to scale out, not only past thread boundaries, but also across network boundaries.
Behaviour
In order to handle any messages, actors have some behaviour associated with them. Actors are then scheduled to process messages in the queue at any time in the future. In order to ensure the safety of any state within an actor, the messages are processed one by one in first-in, first-out order until the mailbox is empty. Within this behaviour actors are able to perform a number of other operations, like setting their behaviour for the next message, sending messages onto other actors and spawning other actors.
Communication
One of the key aspects of the actor model is the underlying means of communication between actors. Rather than requiring a direct reference to anything the actor will need to use, it instead communicates by sending a message to an address. By removing the concept of a direct reference, this ensures that components are loosely coupled. An actor has a mailbox with an associated address. Whenever it receives a message, it’s added to the end of the queue. Actors are able to communicate with absolutely any actor within the actor system or even in other actor systems. Actors can even send messages to themselves, which is particularly useful in the event that it needs to process the results of some long-running task after it’s dealt with all other messages in the queue.
Where does Akka.Net come from?Akka.Net is a port of the Akka library, originally written for the JVM, to the CLR. The intital implementation of Akka was released in 2009 after work by Jonas Bonér. It has since been used in a number of significant product releases, including those from companies such as Twitter. It also forms a large underpinnning of the Apache Spark project. Akka.Net aims to bring a port of Akka to the CLR by staying as true to the original implementation whilst also ensuring it is usable in an idiomatic way from both C# and F#. |
The actor model is, in essence, similar to how humans communicate on a day-to-day basis. For example, if you tell somebody that you want him to do something, you pass him a message in the form of a statement. The person at the other end then responds to that message in the appropriate way. It may be that he isn’t able to perform the task at the moment and so he ignores your message. You don’t have to sit and wait for him to do it. You can go and do other work. When that person completes the work, he may send you a message back saying that the work is complete.
Due to the targeted nature of messages in the actor model, it allows us to simply forget about a number of difficult concepts such as the where an actor is deployed.
 |
Why the need for reactive systems? By Anthony Brown This article was excerpted from the book Reactive Applications with Akka.NET. |