

By Enrico Buonanno
In this article, I’ll use a simple example that illustrates why pure functions should be your weapon of choice when writing code for parallel and, more generally, concurrent execution.
Pure functions are functions that have no side effects (such as changing state or doing I/O), and whose output is strictly determined by their input arguments.
Here is our simple scenario: you’d like to format a list of strings as a numbered list; the casing should be standardized, and each item preceded with a counter. To do this, we want to create a ListFormatter class that can be used as follows:
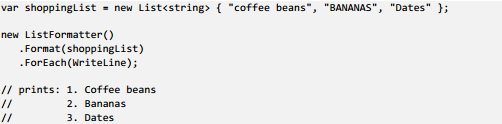
Ok, so that’s our requirement. Now, let’s look at a possible implementation for ListFormatter:
Listing 1: A list formatter combining pure and impure functions

- A pure function
- An impure function, since it mutates global state
- Pure and impure functions are applied similarly
There are a few things to point out with respect to purity:
- ToSentenceCase is pure (its output is strictly determined by the input). Since its computation only depends on the input parameter, it can be made static without any problems.
- PrependCounter increments the counter, so it’s impure. Since it depends on an instance member — the counter — we cannot make it static.
- In the Format method, we apply both functions to items in the list with Select, irrespective of purity. This is something that may well change in future programming languages.
If the list was big enough, would it make sense to perform the string manipulations in parallel? Could the runtime decide to do this, as an optimization? We’ll tackle these questions next.
Pure functions parallelize well
Given a big enough set of data to process, it’s usually advantageous to process it in parallel, especially when the processing is CPU-intensive and the pieces of data can be processed independently.
The problem is that pure and impure functions do not parallelize equally well, and I’ll illustrate this by trying to parallelize our list formatting functionswith our ListFormatter. Pure functions parallelize well, and more generally are immune to the issues that make concurrency difficult.
Compare the expressions:
![]()
In the first, we’re using the Select method defined on Enumerale to apply the the pure function ToSentenceCase to each element in the list. The second expression is very similar, but we use methods provided by Parallel LINQ (PLINQ).
AsParallel turns the list into a ParallelQuery. As a result, Select resolves to the implementation defined on ParallelEnumerable, which will apply ToSentenceCase to each item in the list, but now in parallel (that is, the list will be split into chunks, and then several threads will be fired off to process each chunk). In both cases, we’re then using ToList to harvest the results into a list.
As you would expect, the two expressions yield the same result, but one does so synchronously and the other in parallel. This is nice: just one call to AsParallel and we get parallelization almost for free.
But this raises the questions: Why “almost” for free? Why can’t we have it for free? In other words, why do we have to explicitly instruct the runtime to parallelize the operation? Why can’t it just figure out that it’s a good idea to parallelize the operation, just like it figures out when it’s a good time to run the garbage collector?
The answer is that the runtime doesn’t know enough about the function being applied, to make an informed decision of whether parallelization may change the program flow. Because of their properties, pure functions can always be applied in parallel, but as we pointed out, the runtime does not know about the purity of the function being applied, and this is why I expect future languages to be different in this respect.
Parallelizing impure functions
Let’s see what happens if we naively apply parallelization with the impure PrependCounter function:
![]()
Since PrependCounter increments the counter variable, in the parallel version we will have multiple threads reading and updating the counter concurrently. As is well known, ++ is not an atomic operation, and since there is no locking in place we will lose some of the updates, and end up with an incorrect result.
If you test this approach with a big enough input you will get an error along the lines of:

This should all sound pretty familiar if you have some multithreading experience. Because multiple processes are reading and writing to the counter at the same time, some of the updates are lost. You probably know that this could be fixed by using a lock or the Interlocked class when incrementing the counter. But locking is an imperative construct that we would rather avoid when coding functionally.
Let’s summarize what we learned from the above. Unlike pure functions, whose application can be parallelized by default, impure functions don’t parallelize out of the box. And, since parallel execution is non-deterministic, you may get some cases in which your result is correct, and others in which it isn’t (not the sort of bug we like to face).
Being aware of whether your functions are pure may help you understand and prevent these issues. Furthermore, if you develop with purity in mind, it will be easier to parallelize execution, if you decide to do so.
Avoiding state mutation
Instead of locking, another way to avoid the pitfalls of concurrent updates is to remove the problem at the source; that is, don’t use shared state to begin with! How this is done naturally varies for each scenario, but I’ll show a solution to the current scenario, that enables us to format the list in parallel.
Let’s go back to the drawing board and see if we can have a non-parallel solution that does not involve mutation. What if, instead of updating a running counter, we generate a list of all the counter values we need, and then “pair” items from the list with item from the list of counters?
For the list of integers, we can use Range, a convenience method on Enumerable.
Listing 2: Generating a range of integers
![]()
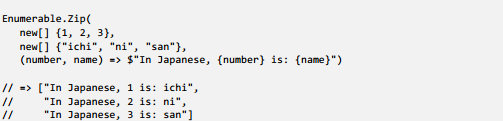
The operation of “pairing” two parallel lists is a common operation in FP, and it’s called Zip.
For example:
Listing 3: Combining elements from parallel lists with Zip
Using Range and Zip, we can rewrite our list formatter as follows:
Listing 4: List formatter refactored to use pure functions only
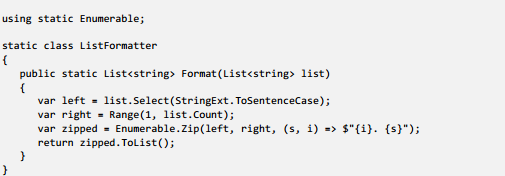
Here, we use the list, with ToSentenceCase applied to it, as the “left side” of Zip. The “right side” is constructed with Range. The 3rd argument to Zip is the “pairing function”: what we will do with each pair of items.
Zip can be used as an extension method, so we would usually write the Format method using a more fluent syntax:

After this refactoring, Format is pure and can safely be made static. What about making it parallel? Well, now it’s a piece of cake, because PLINQ offers an implementation of Zip that works with parallel queries. A parallel implementation of the list formatter would then look like this:


- Turn the original data source into a parallel query
- Use the Range exposed by ParallelEnumerable
This is almost identical to the non-parallel version: there are only two differences. First, we turn the input list into a ParallelQuery, so that everything after is done in parallel. Second, we changed the using static, with the effect that we will call the Range method defined on ParallelEnumerable (this returns a ParallelQuery, which is what the parallel version of Zip expects). The rest is just as in the non-parallel version, and the parallel version of Format is stil a pure function.
In this case, ParallelEnumerable does all the heavy lifting for us, and we were able to easily resolve the problem by reducing our specific scenario to the more common scenario of zipping two parallel sequences — a scenario common enough that it’s addressed in the framework.
While in this scenario we enabled parallel execution by removing state updates altogether, doing so will not always be this easy. But hopefully the ideas shown will put you in a better position when tackling issues related to parallelism, and more generally concurrency.
 |
Functional Programming in C#: Purity and Concurrency |