

By Hari Yadav
The Context
Data comprises information, information supports decision making, decisions drive processes further that produces results in terms of revenue. Now, take a step back and think about a scenario where the quality of data is poor. If you can think of consequences, you understood the importance of data quality systems.

Figure 1: The data processing process
Problems Caused by Poor Data Quality
Currently, every enterprise is exploding with data, the amount of data generated by social media, consumer behavior, the various system in the enterprise, and mobile devices. Every action by human and machine is generating data in various formats and sizes and organizations are using this data to understand human and systems behaviors. Data is the biggest asset for any organization if presented and used well, but all this depends on the quality of data. Poor data quality can substantially damage your organization’s reputation and it can also cost valuable revenue. Here are some problems caused by poor data quality:
- Extra time to reconcile
- Loss of credibility in system
- Lost revenue
- Customer dissatisfaction
- Compliance problems
- System integration issues
What Is Data Quality?
There a no definition for data quality as such but data is considered “good” if it can fulfill the underlying need of extracting information out of data. So, data quality is tightly integrated with the context in which it is used. For example, the word “MSFT” (stock ticker for Microsoft) will be considered good for the stock exchange but you rather will use Microsoft if you have to mail something to the Microsoft office.
If the ISO 9000:2015 definition of quality is applied, data quality can be defined as the degree to which a set of characteristics of data fulfills requirements. Examples of characteristics are completeness, validity, accuracy, consistency, availability, and timeliness.
How to Solve Data Quality Problems
There is no unique or straightforward solution to every data quality problem, but you can follow the pattern to improve the quality of your data over time. Whether you use proprietary tools or develop your own, following are the concepts you would go through:
Data Cleansing/Data Scrubbing
The process of correcting the source data and eliminating the dirty data is known as cleansing or cleaning. Dirty data could be in form of incorrect data, irrelevant data, or incomplete data. Following will be part of this process:
- Correct data based on some standard/knowledge base
- Correct data based on their data types
- Correct data formats
- Remove duplicate records
- Define hierarchies between data sets
Matching
Matching is the process of identifying, linking, or merging related entries within or across the data sets. In simple words, you run a search against the same data set and the existing data set to find out if records already exist. The only thing is this case is that you are running an exact match rather than weight-based matching. In weighted matching, you assign some weight to each search criterion and then calculate the final matching score to determine whether two records match. If the final score is greater than the minimum matching score, the two records considered as a match.
Data Profiling
Data profiling is the process of validating data against industry standard, company defined measures, and business rules to verify that data matches the appropriate description. It can establish trends and commonalities in the information supplied.
Data Monitoring/Administration
This is more of a data quality process monitoring where you define controls or monitor process execution and set alerts to notify users for failed processes and define controls to keep compliance in check with policies.
One of the solutions available to cater to data quality issues is Data Quality Services from Microsoft. It is a SQL server-based solution. The following section contains basic information about SQL Server Data Quality Services (DQS).
SQL Server Data Quality Services
Data Quality Services (DQS) is a Knowledge-Driven data quality solution that helps organizations define data quality processes, execution, and monitoring of defined processes/workflows to improve the quality of their data. It’s extensible with a knowledge base from various third-party providers and you can create a knowledge base by yourself. Following are steps to define, use, and monitor the data quality services:
- Map: The source data to data quality systems data store.
- Define and manage: You have to train your system before you can use it to validate data. This process is known as knowledge base management. You also can subscribe for knowledge bases available via the Azure marketplace.
- New projects: Use the knowledge base to correct and standardize data for each data quality project.
- Continuously improve: Fine tune the data quality process, either by defining more knowledge bases or matching policy rules.
- Control and monitor: DQS provides administration capability for access control and monitoring the process over time.
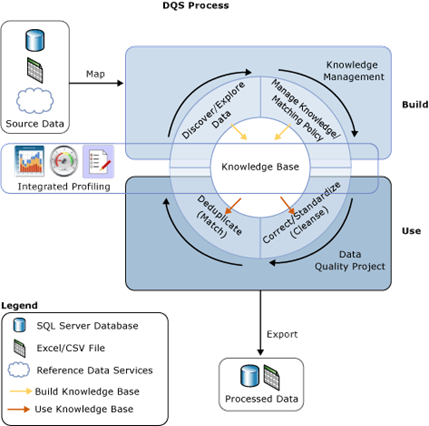
Figure 2: The DQS process
Borrowed from Microsoft
Data Quality Services Installation and Explanation
Microsoft first introduced Data Quality Services with SQL Server 2008 and, due to little awareness and appreciation of master data management systems and data quality systems at the time, it is hardly surprising that its introduction went mostly unnoticed. Subsequent versions of SQL Server 2012, 2014, and 2016 brought some new features and product stability to DQS, too. With SQL Server 2016, Data Quality Services capabilities are now of similar quality and sophistication as any other enterprise-grade data quality solutions.
The following installation instructions are based on SQL Server 2016 available on the Microsoft Azure Cloud platform and should work fine with other DQS versions supported on SQL Server as well.
- Log in with your Azure account or create an Azure account if you have not done so already.
- Search for a virtual machine with the following name: “SQL Server 2016 RTM Enterprise on Windows Server 2012 R2.”
- Follow the simple ‘provisioning VM’ wizard, which mostly involves clicking ‘next-next’ with some occasional user inputs. Be sure to carefully note down the details as you go, especially the credentials.
- Start the recently created virtual machine, and note down the public IP address that is assigned to it.
- You can ‘remote desktop’ into the virtual machine by using its public IP address once it is fully up, running, and operational. This might take a while depending on your VM capacity.
- This virtual machine has pre-installed SQL Server 2016.
Data Quality Services has two components: Data Quality Server and Data Quality Client.
Data Quality Server
To install Data Quality Server:
- Go to Start and then Apps.
- Go to Microsoft SQL Server 2016 and select SQL Server 2016 Data Quality Server installer.
- The launched command line installer will ask for some user inputs.
- It will install Data Quality Server on top of the SQL Server database engine.
- The following three databases will be created as part of the installation process:
- DQS_MAIN: Contains DQS stored procedures, engine, and knowledge bases
- DQS_PROJECTS: Contains data quality projects information, which is none as this point
- DQS_STAGING_DATA: The area where you will import your data from source to run data quality operations
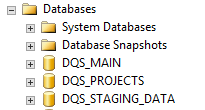
Figure 3: The Databases file system
Data Quality Client
Data Quality Client is a graphical user interface to perform data quality operations and administrative tasks. You can install the client on the same server where DQS server is installed, or you can install it separately and then connect remotely to the server. Launching Data Quality Client will serve the following user interface;
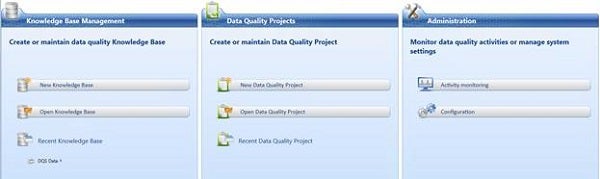
Figure 4: The three interfaces available
Knowledge Base Management
Knowledge Base is the underlying set of facts, assumptions, and rules that a computer system has available to solve a problem. It is a store of information or data that is available to draw on. This is where you can define your data quality needs by creating domains or composite domains. You also can import knowledge from external sources/vendor APIs. You can define rules, policies for data validation, cleansing, and matching. DQS comes with a pre-built Default Knowledge Base, and it contains the domains like Country/Region, US-Counties, US-Last Name, US-State, and so forth.
Data Quality Projects
Once the knowledge base is created or you have configured an external API for knowledge base, you can start using it for all your projects. The data quality project is the area where you define your data source, configure knowledge base to validate against, and make it a repeatable process. All cleansing and matching activities are performed here.
Administration
Monitoring of data quality activities and system settings can be managed under this option. You can configure the system for things like a marketplace setting for reference services, and so on.
Summary
It’s hard to ignore the value of data in today’s time and that is why every organization is investing religiously in initiatives like big data, business intelligence, building data lakes, master data management, and the like. The value delivered by these data-centric initiatives directly depends on the quality of data. So, it is imperative to focus and invest on developing or using data quality products. Data quality investment is going to be small chunk of your overall budget, but it is going to multiply your returns by a big factor.