

There isn’t a test that can be run on a page to check if it is clean and simple. You can check whether a page is valid with a number of tools. But you won’t find a tool that tells you whether a page is clean and simple. Creating pages that are clean and simple is a design principle; it is a goal to keep in mind when you write the HTML, CSS, and JavaScript code that make up a page. This article shows you some methods that will help you achieve this goal.
Producing Valid HTML
Fact: most web pages are invalid. In 2001, Dagfinn Parnas analyzed the code of 2.4 million web sites and concluded that less than 1 percent of the pages were valid HTML. More recent studies looked at the home pages of the organization members of the W3C and at the sites of well-known bloggers who write about web standards. Although you might expect the sample of individuals and organizations selected in those two studies to be more likely to use valid HTML on their sites, the studies concluded that even for this sample the percentage of valid HTML is in the low single digits.
The reason we have so much invalid HTML on the web today is that historically browsers have been going to great lengths trying to render invalid HTML. The initial goal was to make the life of the HTML author easier: even if your HTML is not really valid, the browser will not complain and will display something based on some heuristic. In most cases the browser is able to make correct assumptions, and the page comes out just as you intended. Historically, as features were added to HTML, browsers became larger pieces of software, with a lot of code implementing those heuristic dealings with invalid HTML. And with just a small percentage of web pages being valid, you can safely bet that browsers will continue to support invalid HTML as they do today for the foreseeable future.
Then what is your incentive for writing valid HTML? After all, you just want your page to be rendered by the browser the way you intended. So as long as you get the intended result, why would it matter if the HTML sent to the browser is valid or invalid? We will argue here that it does matter, and that producing valid HTML has direct benefits for you, the web developer.
We all know that there are differences between browsers: a given page might look fine under Firefox and Safari, but will have problems with Internet Explorer, or vice versa. Browsers implement the HTML specification more or less closely and may make different assumptions because there is room for interpretation in the specifications or just simply because they have bugs. But handling invalid HTML is completely outside of the scope of the HTML specification. So when it comes to invalid HTML, browsers are on their own, and in our experience you are much more likely to see differences between browsers with invalid HTML than with valid HTML. So you will benefit from generating valid HTML just for that reason.
But there is more: in the Web 2.0 world, your work does not stop after the browser has rendered your page the way you intended. You are likely to also send to the browser JavaScript code that will modify what is displayed by the browser as the user interacts with the page. You do so in JavaScript by modifying a tree of objects called the Document Object Model (DOM). Chapter 2, “Page Presentation,” of the book, Professional Web 2.0 Programming (Wrox, 2006, ISBN: 978-0-470-08788-6) looks at the DOM in more detail. Here, suffice to say that the DOM is a tree of objects that represent the structure of the page. For example, consider this snippet of HTML:
<ol>
<li>Page Presentation</li>
<li>JavaScript and Ajax</li>
</ol>
When rendered by the browser, it will look something like this:
1. Page Presentation
2. JavaScript and Ajax
Now imagine that text in each list item becomes longer. To make the list easier to read you decide it makes sense to make each list item a paragraph; this way the browser will add some space between each item. You do this by modifying the HTML as follows:
<ol>
<p><li>Page Presentation</li></p>
<p><li>JavaScript and Ajax</li></p>
</ol>
Can you see the error? Yes, the paragraph should go inside the <li> element, instead of going around it. But if you write the preceding code, chances are you won’t even find out about your mistake because the browser will render it just fine and give you the expected result. If this appears in a static page, and the page renders as you expect, there isn’t much harm done. However, now consider that you have a button on the page that moves the second item in the list to the first position. For this you add IDs on the <li> elements:
<ol>
<li id="first">Page Presentation</li>
<li id="second">JavaScript and Ajax</li>
</ol>
<script type="text/javascript">
function invert() {
var first = document.getElementById("first");
var second = document.getElementById("second");
var parent = first.parentNode;
parent.insertBefore(second, first);
}
</script>
<button onclick="invert()">Invert</button>
This code essentially takes the element with ID "second" and moves it before the element with ID "first". Now one would expect the same code to work if you add a <p> element around <li> and move the ID to the <p> element, as in:
<ol>
<p id="first"><li>Page Presentation</li></p>
<p id="second"><li>JavaScript and Ajax</li></p>
</ol>
In this case your code does not work. It does not work because you have wrongly assumed that the browser saw your HTML the way you wrote it and created a DOM that looks like Figure 1.
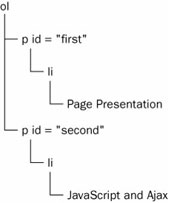
Figure 1
Instead, Internet Explorer and Firefox create a DOM that looks like Figure 2. Note that because this DOM is created by the browser based on invalid HTML, it is entirely possible for other browsers to create yet another DOM, further complicating the issue.

Figure 2
When you move the element with ID "second" before the element with ID "first", you are moving an empty paragraph before another empty paragraph. The code certainly runs fine; it does not cause any error, but it doesn’t do what you expected. When confronted with invalid HTML code, the browser will still render it, and in some cases the result will be what you expect. However the DOM the browser creates might not match the structure of your HTML. When this happens, your JavaScript may not work as expected, and figuring out why it doesn’t can be quite time consuming.
The lesson is that by producing valid HTML code you will see fewer differences in the way different browsers render your HTML, and you can avoid problems down the road when the HTML is dynamically manipulated by JavaScript code.