

Identifiers
Identifiers are names given to namespaces, classes, methods, variables, and interfaces. An identifier must be a whole word and start with either a letter or an underscore. It can be any combination of letters, numbers, and underscores. But, it should not start with a number. Prior to .NET, programmers were using Hungarian-notation guidelines for naming identifiers; however, with .NET Microsoft has recommended Pascal and Camel notations for identifiers. They have also suggested using semantics in the identifier name. Another point you should bear in mind is that identifiers should not be the same as a C# keyword as listed in the section “Keywords.” For example, the following code is illegal:
// Error. int cannot be used as a variable name as it a keyword
int int = 5;
Identifiers in C# are case sensitive. For instance, X is not equal to x. Some programmers use the @ prefix as a first character when declaring identifiers to avoid a clash with a keyword, but it is not a recommended practice. The following names are valid identifiers in C#:
- Hello
- hello
- H_ello
- HelloWorld
- X
- x
Note: In C#, class names can be different from file names.
You should name the variables using the standard DataType prefixes. Also, the first letter after the prefix should be capitalized. Table 1.6.1 shows a list of prefixes for the various .NET DataTypes. You will learn more about DataTypes in Part 3 of C#—Learning with the FAQs.
Table 1.6.1 List of C# Data Types
| Data Type | Prefix | Example |
| Array | arr | arrNumber |
| Boolean | bln | blnSelect |
| Byte | byt | bytNumber |
| Char | chr | chrPick |
| DateTime | dtm | dtmPick |
| Decimal | dec | decPoint |
| Double | dbl | dblData |
| Integer | int | intVar |
| Long | lng | lngMiles |
| Object | obj | objVar |
| Short | shr | shrNumber |
| Single | sng | sngNumber |
| String | str | strAddress |
Interfaces are usually named with an “I” as the first letter. All Windows Forms controls should be named with the special prefixes, as shown in Table 1.6.2. This is to avoid confusion and also to distinguish among other controls in a complex project. As explained above, the first letter after the prefix should be capitalized. Once you master the naming conventions and prefixes, it will be very easy for you to write and debug the code at a later stage.
Table 1.6.2 List of prefixes for Windows Forms controls
| Control Name | Prefix | Example |
| Button | btn | btnSubmit |
| TextBox | txt | txtFname |
| CheckBox | chk | chkHobbies |
| RadioButton | rad | radMale |
| Image | img | imgIndia |
| Label | lbl | lblCity |
| Calendar | cal | calDate |
It is beyond the scope of this FAQ to cover the prefixes of all the .NET controls. You will find a detailed list of them in the MSDN Library. (Perform a search using the phrase “naming guidelines”)
Keywords
Keywords are special words built into the C# language and are reserved for specific use. This means you cannot use them for naming your classes, methods, and variables. For instance, if you attempt to use a C# keyword ( if ) as your class name, the C# compiler will emit a runtime error, as shown in Figure 1.6.1.
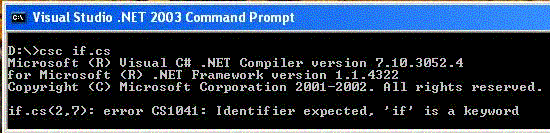
Figure 1.6.1
To resolve the problem, you may have to change the class name to some other meaningful name. There are around 80 keywords in C#. They are listed in the table given below.
Table 1.6.3 List of C# Keywords
| abstract as |
base bool break byte |
case catch char checked class const continue |
decimal default delegate do double |
| else enum event explicit extern |
false finally fixed float for foreach |
goto | if implicit in int interface internal is |
| lock long |
namespace new null |
object operator outo override |
params private protected public |
| readonly ref return sbyte sealed |
this throw true try typeof |
uint ulong unchecked unsafe ushort using |
short sizeof stackallac static string struct switch |
| virtual void |
For more detailed information about this topic, perform a search on the MSDN Library with the phrase “C# keywords.”