

Introduction
As you know, new/delete operations take a lot of CPU time. If you work with servers, CPU time is important. If additional memory is added to the server, the servers’ available memory size will grow in a linear fashion. However, CPUs don’t behave the same (dual CPUs doesn’t necessarily mean twice the speed of a one-CPU situation.) So, common server code has its own efficient memory management system. VMemPool is the one of them for me.
About the Implementation
CVMemPool is a generic (template) class because I assumed the client would want a similar usage as new/delete. So, by using CVMemPool, you can code like it’s a general pointer.
CObj* p = new CObj;
p->do();
delete p;
CVMemPool has its own ‘allocation table’ implemented by using a circular queue, so you can check whether a pointer in a pool is valid by using vmIsBadPtr. You also can check how many objects are allocated in the pool by using vmGetPoolInfo.
CVMemPool has two template variables, class objT and DWORD _dwPoolSizeT = 1000. _dwPoolSizeT is the size of the pool. You can reconfigure the pool size with this variable. objT should not be important to you. If objT is absent and you have a different class, make the object as below.
// suppose CVMemPool is like below. It's not real code.
template <DWORD _dwPoolSizeT = 1000>
class CVMemPool
{
...
};
class CObj1 : public CVMemPool<>
{
...
};
class CObj2 : public CVMemPool<>
{
...
};
CObj1 c1;
CObj2 c2; // It will share a pool with c1. It is not good
// because I need objT.
As you know, when a compiler sees the last instancing code, it will think c1 and c2 are the same template class layout, so it makes only one virtual pool (because CVMemPool<T,F>::ms_pMemPool is static.)
Usage
//make class in pool.
class CObj : public CVMemPool<CObj>
{
...
};
// and you can use it same like general new/delete code.
CObj* p = new CObj; // Pool is created, and allocation in
// first pool block.
CObj* p2 = new CObj; // second pool block will be used.
delete p; // first block will be freed.
delete p2; // second, too.
Performance
Test environment
P4 1.6GHz, 256 Mb RAM, Windows 2000 Professional, release executable testing. Two situations tested:
first, CObj is 1,000 bytes size and loop new and delete 10,000 , 20.000 ….
first, CObj is 10,000 bytes size and loop new and delete 10,000 , 20.000 ….
( n * 1,000 is wrong, n* 10,000 is right, sorry )
The results are below.
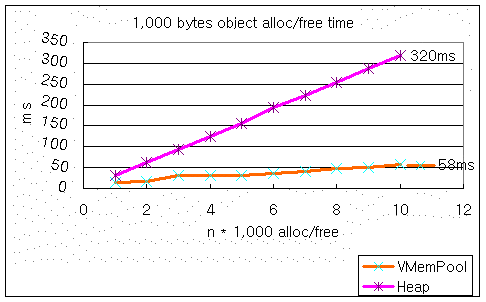
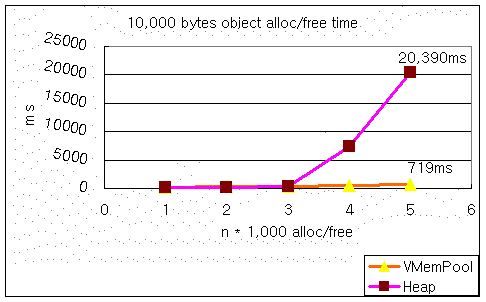
I can’t say that these results are exactly right, but I think CVMemPool will be better than the default heap operation (new/delete) on the server side, or on the client side for some CPU’s.
In the second situation, I tested 6,000 or over, but I couldn’t see the result on the ‘Heap’ because the program gave a fatal error—insufficient memory—surely, CVMemPool works well and fast.
I hope it helps you. Thanks a lot!