

Short History
Probably the best-known character set is the 7-bit char set known as ASCII. It stands for American Standards Committee for Information Interchange and was designed for communication in US English. It contains 128 different characters, including lowercase and uppercase letters, digits 0-9, various punctuation marks, non-printing characters (new line, tab, and so forth), and control characters (null termination, backspace, bell, delete, and so on).
But, because it was designed to handle English, there were problems with European languages that need diacritics (special marks added to a letter to indicate a special pronunciation). As a result, ASCII was extended and several char codes with 255 codes were created. One of them, often called IBM character set, uses the characters with numeric value between 128–255 (having the most significant bit set to 1) for graphics and line drawing and some special European characters. Another 8-bit character set is ISO 8859-1 Latin 1 (also called simply ISO Latin-1). Characters with numeric value between 128–255 are used to encode characters specific to languages that are written in some approximation of Latin alphabet, hence the name.
European languages are not the only ones spoken and written around the planet; African and Asian languages were not supported by 8-bit character sets. The Chinese alphabet alone has more than 80,000 different characters (or pictograms). However, combining similar characters from Chinese, Japanese, and Vietnamese, so that some chars represent different words in different languages, they, along with languages from Europe, Africa, Middle East, and other regions can be encoded in just 2 bytes. And so, UNICODE was created. It extends ISO Latin-1 by adding an extra high-order byte. When this byte is 0, the character in the low-order byte is an ISO Latin-1 character. UNICODE offers support for alphabets from Europe, Africa, Middle East, Asia (including the unified Han set of East Asian ideograms and the complete ideograms for Korean Hangul). On the other hand, UNICODE does not provide support for Braille, Cherokee, Ethiopic, Khmer, Mongolian, Hmong, Tai Lu, Tai Mau, and the like. (Mongolian is commonly written using the Cyrillic alphabet and Hmong can be written in ASCII). It also does not provide support for many of the archaic languages, such as Ahom, Akkadian, Aramaic, Babylonian Cuneiform, Balti, Brahmi, Etruscan, Hittite, Javanese, Numidian, Old Persian Cuneiform, Syrian, and many others.
It proves that many times using UNICODE texts that can be written in ASCII is inefficient, because the UNICODE text has a double size than the same text in ASCII, half of it being nothing but zeros. To handle this problem, several intermediate formats were created. They are called Universal Transformation Format, or simply UTF. There are currently several forms of UTF: UTF-7, UTF-7.5, UTF-8, UTF-16, and UTF-32. This article is focused on the basics of UTF-8.
UTF-8
UTF-8 is a variant-length character encoding for Unicode, created by Ken Thompson in 1992, in a New Jersey diner, where he designed it in the presence of Rob Pike on a placemat. It is currently standardized as RFC 3629. UTF-8 uses 1 to 6 bytes to encode one UNICODE character. (If the UNICODE char is represented on 2 bytes, there is a need for mostly 3 bytes; if the UNICODE char is represented as 4 bytes, 6 bytes may be needed.) 4 or 6 bytes to encode a single char may seem too much, but the UNICODE chars that need that are rarely used.
The transformation table for UTF-8 is presented below:
| UNICODE | UTF-8 |
| 00000000 – 0000007F | 0xxxxxxx |
| 00000080 – 000007FF | 110xxxxx 10xxxxxx |
| 00000800 – 0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 00010000 – 001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 00200000 – 03FFFFFF | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 04000000 – 7FFFFFFF | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
The UNICODE characters that actually represent ASCII chars are encoded in a single byte, and the UTF-8 representation is actually the ASCII representation. All other UNICODE characters require at least 2 bytes. Each of these bytes starts with an escape sequence. The first byte has a unique sequence, composed on N bits on 1 followed by 1 bit of 0. The N number of bits of 1 indicates the number of bytes on which the character is encoded.
Examples
UNICODE \uCA (11001010) requires 2 bytes for UTF-8 encoding:
\uCA -> C3 8A
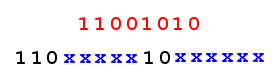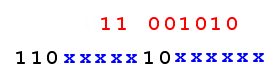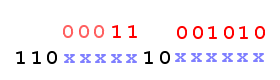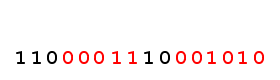
UNICODE \uF03F (11110000 0011111) requires 3 bytes for UTF-8 encoding:
\u F03F -> EF 80 BF
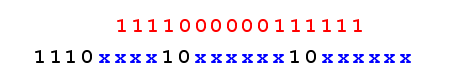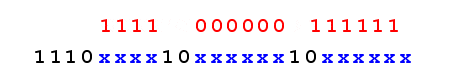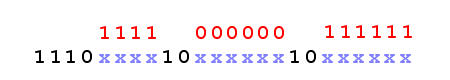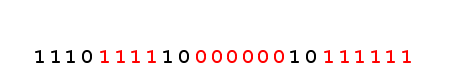
Advantages
Here are several advantages of UTF-8:
- UTF-8 can be read and written quickly just with bit-mask and bit-shift operations.
- Comparing two char strings in C/C++ with strcmp() gives the same result as wcscmp(), so that legicographic sorting and tree-search order are preserved.
- Bytes FF and FE never appear in an UTF-8 output, so they can be used to indicate an UTF-16 or UTF-32 text (see BOM).
- UTF-8 is byte order independent. The bytes order is the same on all systems, so that it doesn’t actually require a BOM.
Disadvantages
UTF-8 has several disadvantages:
- You cannot determine the number of bytes of the UTF-8 text from the number of UNICODE characters because UTF-8 uses a variable length encoding.
- It needs 2 bytes for those non-Latin characters that are encoded in just 1 byte with extended ASCII char sets.
- ISO Latin-1, a subset of UNICODE, is not a subset of UTF-8.
- The 8-bit chars of UTF-8 are stripped by many mail gateways because Internet messages were originally designed as 7-bit ASCII. The problem led to the creation of UTF-7.
- UTF-8 uses the values 100xxxxx in more than 50% of its representation, but existing implementation of ISO 2022, 4873, 6429, and 8859 systems mistake these as C1 control codes. The problem led to the creation of UTF-7,5.
Modified UTF-8
Java uses UTF-16 for the internal text representation and supports a non-standard modification of UTF-8 for string serialization. There are two differences between the standard and modified UTF-8:
- In modified UTF-8, the null character (U+0000) is encoded with two bytes (11000000 10000000) instead of just one (00000000), which ensures that there are no embedded nulls in the encoded string (so that if the string is processed with a C-like language, the text is not truncated to the first null character).
- In standard UTF-8, characters outside the BMP (Basic Multilingual Plain) are encoded using the 4-byte format, but in modified UTF-8 they are represented as surrogate pairs and then the surrogate pairs are encoded individually in sequence. As a result, characters that require 4 bytes in standard UTF-8 require 6 bytes in modified UTF-8.
Byte Order Mark
BOM is a character that indicates the endianness of a UNICODE text encoded in UTF-16, UTF-32 and in the same time a marker to indicate that text is encoded in UTF-8, UTF-16, UTF-32 (UTF-8 is byte-order independent).
| Encoding | Representation |
| UTF-8 | EF BB BF |
| UTF-16 Big Endian | FE FF |
| UTF-16 Little Endian | FF FE |
| UTF-32 Big Endian | 00 00 FE FF |
| UTF-32 Little Endian | FF FE 00 00 |
UTF-8 C++ Encoding Sample
Here are four functions written in C++ that encode and decode 2 and 4 bytes UNICODE text in/from UTF-8.
#define MASKBITS 0x3F
#define MASKBYTE 0x80
#define MASK2BYTES 0xC0
#define MASK3BYTES 0xE0
#define MASK4BYTES 0xF0
#define MASK5BYTES 0xF8
#define MASK6BYTES 0xFC
typedef unsigned short Unicode2Bytes;
typedef unsigned int Unicode4Bytes;
void UTF8Encode2BytesUnicode(std::vector< Unicode2Bytes > input,
std::vector< byte >& output)
{
for(int i=0; i < input.size(); i++)
{
// 0xxxxxxx
if(input[i] < 0x80)
{
output.push_back((byte)input[i]);
}
// 110xxxxx 10xxxxxx
else if(input[i] < 0x800)
{
output.push_back((byte)(MASK2BYTES | input[i] >> 6));
output.push_back((byte)(MASKBYTE | input[i] & MASKBITS));
}
// 1110xxxx 10xxxxxx 10xxxxxx
else if(input[i] < 0x10000)
{
output.push_back((byte)(MASK3BYTES | input[i] >> 12));
output.push_back((byte)(MASKBYTE | input[i] >> 6 & MASKBITS));
output.push_back((byte)(MASKBYTE | input[i] & MASKBITS));
}
}
}
void UTF8Decode2BytesUnicode(std::vector< byte > input,
std::vector< Unicode2Bytes >& output)
{
for(int i=0; i < input.size();)
{
Unicode2Bytes ch;
// 1110xxxx 10xxxxxx 10xxxxxx
if((input[i] & MASK3BYTES) == MASK3BYTES)
{
ch = ((input[i] & 0x0F) << 12) | (
(input[i+1] & MASKBITS) << 6)
| (input[i+2] & MASKBITS);
i += 3;
}
// 110xxxxx 10xxxxxx
else if((input[i] & MASK2BYTES) == MASK2BYTES)
{
ch = ((input[i] & 0x1F) << 6) | (input[i+1] & MASKBITS);
i += 2;
}
// 0xxxxxxx
else if(input[i] < MASKBYTE)
{
ch = input[i];
i += 1;
}
output.push_back(ch);
}
}
void UTF8Encode4BytesUnicode(std::vector< Unicode4Bytes > input,
std::vector< byte >& output)
{
for(int i=0; i < input.size(); i++)
{
// 0xxxxxxx
if(input[i] < 0x80)
{
output.push_back((byte)input[i]);
}
// 110xxxxx 10xxxxxx
else if(input[i] < 0x800)
{
output.push_back((byte)(MASK2BYTES | input[i] > 6));
output.push_back((byte)(MASKBYTE | input[i] & MASKBITS));
}
// 1110xxxx 10xxxxxx 10xxxxxx
else if(input[i] < 0x10000)
{
output.push_back((byte)(MASK3BYTES | input[i] >> 12));
output.push_back((byte)(MASKBYTE | input[i] >> 6 & MASKBITS));
output.push_back((byte)(MASKBYTE | input[i] & MASKBITS));
}
// 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
else if(input[i] < 0x200000)
{
output.push_back((byte)(MASK4BYTES | input[i] >> 18));
output.push_back((byte)(MASKBYTE | input[i] >> 12 & MASKBITS));
output.push_back((byte)(MASKBYTE | input[i] >> 6 & MASKBITS));
output.push_back((byte)(MASKBYTE | input[i] & MASKBITS));
}
// 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
else if(input[i] < 0x4000000)
{
output.push_back((byte)(MASK5BYTES | input[i] >> 24));
output.push_back((byte)(MASKBYTE | input[i] >> 18 & MASKBITS));
output.push_back((byte)(MASKBYTE | input[i] >> 12 & MASKBITS));
output.push_back((byte)(MASKBYTE | input[i] >> 6 & MASKBITS));
output.push_back((byte)(MASKBYTE | input[i] & MASKBITS));
}
// 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
else if(input[i] < 0x8000000)
{
output.push_back((byte)(MASK6BYTES | input[i] >> 30));
output.push_back((byte)(MASKBYTE | input[i] >> 18 & MASKBITS));
output.push_back((byte)(MASKBYTE | input[i] >> 12 & MASKBITS));
output.push_back((byte)(MASKBYTE | input[i] >> 6 & MASKBITS));
output.push_back((byte)(MASKBYTE | input[i] & MASKBITS));
}
}
}
void UTF8Decode4BytesUnicode(std::vector< byte > input,
std::vector< Unicode4Bytes >& output)
{
for(int i=0; i < input.size();)
{
Unicode4Bytes ch;
// 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
if((input[i] & MASK6BYTES) == MASK6BYTES)
{
ch = ((input[i] & 0x01) << 30) | ((input[i+1] & MASKBITS) << 24)
| ((input[i+2] & MASKBITS) << 18) | ((input[i+3]
& MASKBITS) << 12)
| ((input[i+4] & MASKBITS) << 6) | (input[i+5] & MASKBITS);
i += 6;
}
// 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
else if((input[i] & MASK5BYTES) == MASK5BYTES)
{
ch = ((input[i] & 0x03) << 24) | ((input[i+1]
& MASKBITS) << 18)
| ((input[i+2] & MASKBITS) << 12) | ((input[i+3]
& MASKBITS) << 6)
| (input[i+4] & MASKBITS);
i += 5;
}
// 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
else if((input[i] & MASK4BYTES) == MASK4BYTES)
{
ch = ((input[i] & 0x07) << 18) | ((input[i+1]
& MASKBITS) << 12)
| ((input[i+2] & MASKBITS) << 6) | (input[i+3] & MASKBITS);
i += 4;
}
// 1110xxxx 10xxxxxx 10xxxxxx
else if((input[i] & MASK3BYTES) == MASK3BYTES)
{
ch = ((input[i] & 0x0F) << 12) | ((input[i+1] & MASKBITS) << 6)
| (input[i+2] & MASKBITS);
i += 3;
}
// 110xxxxx 10xxxxxx
else if((input[i] & MASK2BYTES) == MASK2BYTES)
{
ch = ((input[i] & 0x1F) << 6) | (input[i+1] & MASKBITS);
i += 2;
}
// 0xxxxxxx
else if(input[i] < MASKBYTE)
{
ch = input[i];
i += 1;
}
output.push_back(ch);
}
}