

Abstract
The model is presented describing software code defects dynamics as the result of the interactions between test and development teams. The model allows for accounting of different regimes of work for both teams and other factors like size of the team, code quality, or software composition. Both the calculation algorithm and analytical solution are presented in this article. The proposed model and calculations are presented as an effective method for the analysis of software bugs.
Introduction
Due to its critical nature, the problems of prediction and estimation of the defects in software code have always caused a lot of attention. There are numerous papers and reports focusing on this area. You can find a good review of a multiple models of software defects prediction in the paper “How good is the software: A Review of Defect Prediction Techniques” by B. Clark and D. Zubrow. When trying to apply these models as well as some of the tools, I have found several limitations:
- These models and tools do not describe the dynamics of the defects. They give more or less general characteristics, such as total number of defects at the end of particular phase or year of the project (CostXpert). Other tools, like CaliberRM, give timing dependences of the number of defects, but quite a general formula is used (it’s more a model approximation of the typical data than a dependency that reflects the real specifics of the process.)
- Popular models and a majority of tools are not flexible enough to address the situation where the size of development and test teams may change or the software itself consists of the multiple modules of a different quality.
- Available models normally do not take into account the interaction between multiple teams. For example, development and test teams could work in parallel, exchanging bug reports and new software builds daily, or they can follow almost independent schedules because both teams may be involved in multiple projects and products.
There is always the need to have some handy tool or method that would produce meaningful data, be specific to the project conditions, and be easy to understand and work with. Although I recognize that good prediction techniques require the collection and analysis of the large volumes of historical data and that such investment will be justified in the long run, I wanted to make some estimates quickly and use the project data currently available. All of these factors resulted in the simple model of software defect dynamics presented below.
Model
Before I go into the model description, I should define some terms. I shall define two types of defects. First, there are defects that exist in code but have not been discovered by the test team. These are latent defects defined as N1. Another type of defect is the active defect—one which has already been discovered by the test team and is in the process of being fixed by the development team. The number of such defects is defined as Na. Rd is the defect detection rate, which describes how quickly the test team finds new defects, while Rf is the fixing rate—the development team speed on fixing the discovered defects. When developers are fixing bugs, they inevitably introduce a new ones with the rate marked as R2g. Then, the set of equations describing the dynamics of both latent and active defects will look as following:
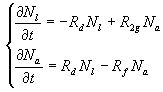
where ![]() and
and ![]()
N0 is the initial number of latent defects. You will see later on how it can be extracted from some real data. The software industry has vast experience with the estimates for this number. The most popular (and simple) estimate is just a percentage derived from the overall number of lines of code or a parameter, which stands for the number of defects per thousand logical lines of code. For the sake of your efforts, assume that you have a reliable estimate for this number driven by the whole size of the code being developed. I also assume that both rates, RD and Rf are known from everyday experience, and I will also omit R2g. These rates can be the function of time (for instance, dealing with the code of a different quality, code reuse, or different teams) and normally are proportional to the number of developers in the teams. Below, I will first show the general approach to the calculation of the number of defects, and then will spend some additional time looking at an analytical solution.
When both rates are functions of time (and potentially number of defects as well), these equations can be solved only numerically by applying the simplest scheme from the numeric computations. By dividing the overall time of interest t by N which defines us the time increment ![]() , the discrete values for the defects of both types can be defined as follows:
, the discrete values for the defects of both types can be defined as follows:
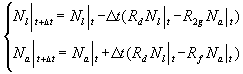
By knowing the values of N1 and Na at the previous time step, the scheme shown above allows you to calculate their values at the next time increment. So, the computer calculation runs in the following loop: You know the initial values for N1 and N1, so you first calculate the value of N1 on the next time interval from the first equation; then, by putting it into the second equation, I calculate the value of Na on the same iteration and put it into the first equation to recalculate N1 on the next time interval. This procedure runs N times until it covers the whole time interval t that you defined initially for your calculations.
This algorithm is very simple. It takes about 20 lines of code in any programming language to implement it and, at the same time, it’s quite flexible. You can account for different timing dependencies of the defect discovery and fixing rates (for example, adding more people in the team, working with the different code, and so forth) or having different regimes of teamwork (one rate can be put to zero for some time interval, accounting for the fact that this team is not currently working) Below are some of the results of our calculations. We present them in a normalized form since our reader is not interested in the project specific data. These graphs show the dynamics of the defects due to the different ratio between Rd and Rf.
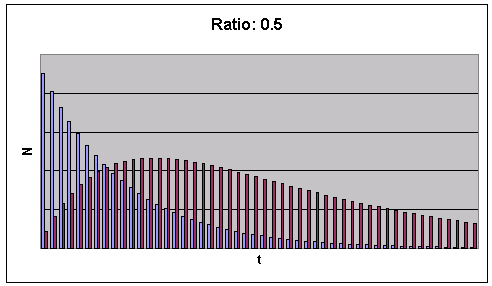
Figure 1: Dynamics of latent (blue) and active (red) defects. 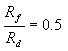
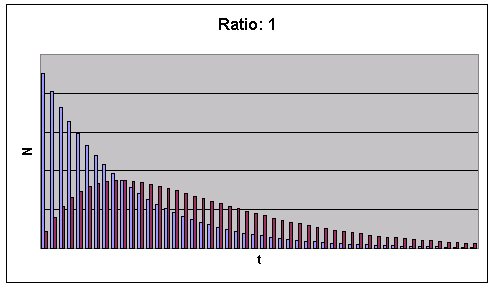
Figure 2: Dynamics of latent (blue) and active (red) defects. ![]()
[Fig.gif]
Figure 3: Dynamics of latent (blue) and active (red) defects. ![]()
It is worth mentioning that even when the rates of defect discovery and correction are equal (refer to Figure 2), additional time is still required for the active defects to be fixed even when the number of latent defects have decreased to a very small number.
The calculation scheme presented above can be easily extended to take into account other factors. For example, a development team does not work in parallel with the test team but will start work on the fixing bugs later on. Then, you will run the iteration process for the first equation only until you reach the time when a development team starts its work and then you’ll start running both equations (obviously with a different initial conditions).
Another example is when some portion of the defects are not really software bugs, but more change requests, enhancements, workarounds, and “nice to have” features. Then, you have to introduce another variable (let’s call it the number of enhancements Ne, which will be dependent on the current number of active defects, and you define the rate of the defects status transformation from the bug into enhancement as Re). Then, your equations describing the defects dynamics will look like the following:
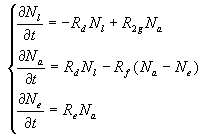
Looking at the computation scheme presented above, one can easily understand how it should be modified to include the third equation into it.
When both rates are not dependent on time and other parameters and you can neglect the rate of the secondary defect generation, these equations have an analytical solution that can be written as in the following:
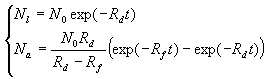
and when ![]() , then
, then ![]()
Analytical formulas for Na (especially the last one) give you a good tool the for validation of the No value (the initial number of “hidden” defects in the code) and checking on the bug fixing rate as well. By having a minimal set of the real data taken from the QA department, I was able to determine the real values for No and confirm the rate values used for the simulation.
The following graph presents a few data points obtained from the QA department and, next to the real data, I put the model approximation; this allowed me to extract all the model parameters from this limited data set.
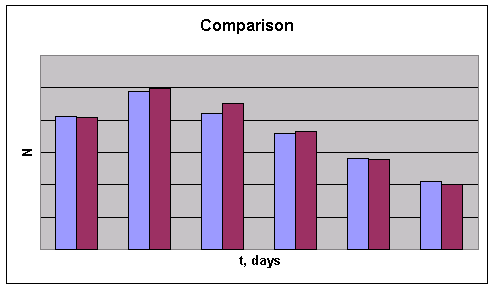
Figure 4: Comparison the real data (blue) and simulated (red) defects. ![]()
Once defined, that model parameters allowed me to perform calculations covering different dates and date ranges of the work, providing both confirmation of the existing production data as well as showing future behavior and the rate of software code improvement.
Conclusion
I believe that the proposed model adequately describes the dynamics of software defects. After extracting model parameters from the short sample of the production data, both the analytical model and the calculation algorithm allow me to estimate the number of software bugs and predict their behavior.
Acknowledgements
The author would like to thank Michelle Ritterhouse, Director of Product Release and Support at CCH, Inc Tax and Accounting for providing real test data and valuable insights on the subject of the paper.
About the Author
Dmitri Ilkaev has about 20 years in software and technology development. He holds a Ph.D. in Computer Sciences from Moscow Institute of Physics and Technology. At the moment of the article submission, Dmitri was working as the Director of Technology at CCH, Inc. (http://www.cch.com) in Torrance, CA. He can be reached at Dmitri_Ilkaev@prosystemfx.com.