

While employing the classical arithmetic compression implementation [1], I found it possible to make some optimizations that significantly increase compression speed, especially on 32+-bit platforms. These optimizations do not alter the original algorithm, are absolutely compatible, and I have not found them mentioned so far. Considerations and changes proposed below are based on the original implementation [1] and hence some acquaintance with it is assumed.
It can be seen that, while looping inside encode_symbol() and decode_symbol(), as soon as the conditions high<Half and low>=Half are not met, they won’t be met again. Moreover, a “bits plus follow” call is needed only once at the beginning; then “output bit” is enough. Here is the encode method structure changed:
do
{
if (high<Half)
{
bit plus follow 0;
}
else if (low>=Half)
{
bit plus follow 1;
low -= Half;
high -= Half;
}
else
break;
for (;;)
{
low = 2*low;
high = 2*high+1;
if (high<Half)
{
output bit 0;
}
else if (low>=Half)
{
output bit 1;
low -= Half;
high -= Half;
}
else
break;
}
}
while (false);
while (low>=First_qtr && high<Third_qtr)
{
bits_to_follow++;
low = 2 * (low – First_qtr); // Subtract offset to middle
high = 2 * (high – First_qtr) + 1;
}
Because only 16 bits of low and high variables are used, these variables are substituted by the combined low_high one.
low_high = low + ((~high) << 16);
Variable high binary negation makes the next optimizations possible: As soon as ~X is equal to -X – 1, ~((~X) << 1) stands for 2 * X + 1. Then,
low = 2*low;
high = 2*high+1;
can be substituted by just:
low_high <<= 1;
The cycle with checking
while (low>=First_qtr && high<Third_qtr)
can be reduced to (taking into account that conditions high<Half and low>=Half are met):
//while (low>=First_qtr && high<Third_qtr)
unsigned long buf = ~low_high;
if (!(buf & 0x40004000))
{
do
{
bits_to_follow++;
//low = 2 * (low – First_qtr); // Subtract offset to
// middle
//high = 2 * (high – First_qtr) + 1;
buf = (buf << 1) + 1 + (First_qtr << 1) –
(First_qtr << 17);
}
while (!(buf & 0x40004000));
low_high = ~buf;
}
Flushing bits to follow can be optimized as well. The flush_bits_to_follow helper is introduced; it simply puts the required amount of one or zero bits to the output:
void bit_plus_follow_0()
{
output_bit_0(); /* Output the bit. */
while (bits_to_follow>0) {
buffer >>= 1; buffer |= 0x80;
/* Put bit in top of buffer.*/
if (–bits_to_go==0) {
/* Output buffer if it is */
flush_bits_to_follow(255);
return;
}
bits_to_follow–;
/* opposite bits. Set */
} /* bits_to_follow to zero. */
}
void output_bit_0()
{
buffer >>= 1; //if (bit) buffer |= 0x80;
/* Put bit in top of buffer.*/
if (–bits_to_go==0) {
/* Output buffer if it is */
PutByte_(buffer);
/* now full. */
bits_to_go = 8;
}
}
void flush_bits_to_follow(int buffer_)
{
for (;;)
{
PutByte_(buffer); /* now full. */
buffer = buffer_;
if (bits_to_follow <= 8)
break;
bits_to_follow -= 8;
}
bits_to_go = 9 – bits_to_follow;
bits_to_follow = 0;
}
However, there is a drawback concerned with code value buffer capacity limitation. It can be fixed by changing the way conditions are checked. For maximal code value buffer size (32 bits for IA32 in this example), the algorithm encoding loop body fragment,
for (;;)
{
if (high < Half)
{
bit plus follow 0;
}
else if (low >= Half)
{
bit plus follow 1;
low -= Half;
high -= Half;
}
else
break;
low = 2*low;
high = 2*high+1;
}
with introduction of the special flags,
long half_flags = ~(low | not_high);
can be changed to:
int shift = num_clear_bits(half_flags);
if (shift != 0)
{
bit_plus_follow(low & Half);
// This loop can be definitely optimized
unsigned long flag = Half;
for (int i = shift; –i > 0;)
{
flag >>= 1;
output_bit(low & flag);
}
low <<= shift;
not_high <<= shift;
}
where num_clear_bits uses an algorithm similar to one of calculating an integer’s logarithm [2]:
const char Table256[] = {
8, 7, 6, 6, 5, 5, 5, 5, 4, 4, 4, 4, 4, 4, 4, 4,
3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
};
inline int num_clear_bits(unsigned long v)
{
unsigned int t, tt; // temporaries
if (tt = v >> 16)
{
return (t = v >> 24) ? Table256[t] : 8 + Table256[tt];
}
else
{
return (t = v >> 8) ? 16 + Table256[t] : 24 + Table256[v];
}
}
The decoding routine can be modified in a similar way. Optimizing multiple bits input/output can further accelerate it.
The complete modified sources can be downloaded as parts of the encoder/decoder code samples. They are implemented as template classes to ease their use with various data providers and consumers.
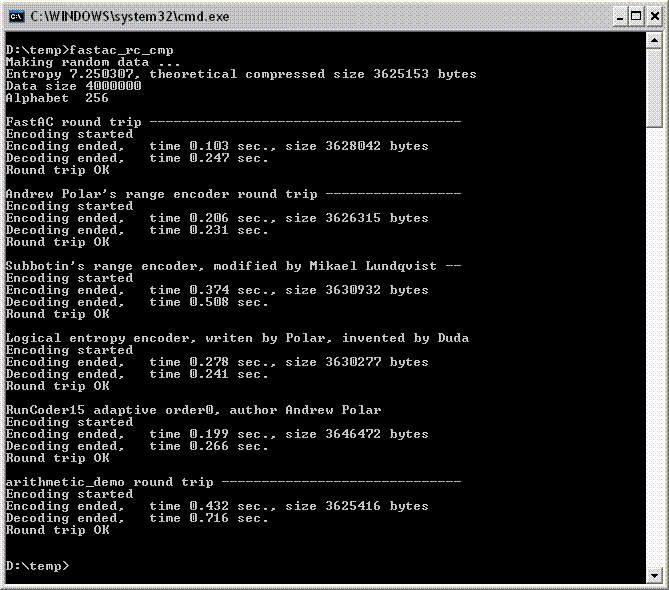
Update: as it has been rightly mentioned by Andrew Polar, the original arithmetic encoder is rather slow. An attempt to see the picture was made based on the FastAC benchmark by Andrew Polar [3] after a couple of improvements. Among other algorithm improvement details, Binary Indexed Trees [4] are worthy mentioning. As it can be seen by results, the original arithmetic encoder (“arithmetic_demo”) is quite slow indeed though it provides marginally better compression ratio.
References
[1] Witten, I. H., Neal, R. M., and Cleary, J. G. (1987) “Arithmetic coding for data compression”, Communications of the ACM, vol. 30, no. 6 (June).
[2] Bit Twiddling Hacks – Find the log base 2 of an integer with a lookup table