

For computer programmers embarking on a project that involves some new API or framework, it is a commonplace occurrence to search out code samples illustrating the various ways in which the API can be utilized. Often this process involves keyword searches describing the API and the functionality that is desired and then performing manual scans of the Web pages associated with the returned links in order to identify code snippets of interest. While a well done code snippet could potentially reveal useful implementation details and save time in the long run, finding relevant snippets can take up a fair share of time in and of itself. Given a programmer’s natural tendency toward automating repetitive tasks, this scenario lends one to wonder if the automatic extraction of topically relevant code snippets could be made a reality.
In answer to this question, this article seeks to describe a means of post processing keyword search results using regular expression based pattern matching as a means of automatic C/C++ code extraction. The basis for the technique entails the building of a set of regular expressions designed to recognize C/C++ functions and control structures and applying these regular expressions to topically relevant results obtained from a search API. For example, if you were interested in code pertaining to bubble sorts, you could use the search API to obtain links pertaining to performing bubble sorts in C/C++, request the Web pages associated with each of the links, and then process the Web pages with the regular expressions to extract elements of C/C++ code. By writing the extracted codes and their corresponding links to an output file, you then have a rapid way of identifying and visually inspecting potentially useful code snippets and their corresponding documentation. While the methodology used will be demonstrated with the Perl programming language, any language that supports http requests and regular expressions could be used to similar effect.
Using the Bing Search API
This technique could be adapted to work with any search API, but for purposes of this article, the Bing API will be used. The main rationale for choosing the Bing API to illustrate the functionality of this code is that of the two major search APIs (Bing and BOSS), Bing is still currently free to use, and thus can let developer’s explore search APIs without a financial commitment. The Bing API can be interacted with by sending http get requests to the service and receiving the results in an XML, JSON, or SOAP format. In this article we will make use of the XML based results. Bing’s XML interface is suitable for applications in which you do not expect your queries to exceed the maximum URI length (2048 characters) and return 414 errors. JSON operates and has limitations similar to the XML interface, but returns results in a way that make it ideal for working with AJAX applications. The SOAP interface is typically reserved for cases in which you suspect that the query lengths and the parameter specifications required by application would exceed the maximum URI length.
Working with the Bing API involves making an http get request that specifies parameters such as your application ID (can be obtained from Bing Developer), your query, and the source you seek to obtain your results from (e.g. the Web, image search, video search, etc). Additionally, there are optional parameters that can be specified as well to control the numbers of results returned, file types, etc.
Now that we have a conceptual understanding of how the Bing API works, let’s take a look at a Perl code sample that implements an API request (Listing 1).
Listing 1: Making a request of the Bing API
use LWP;
my $request=LWP::UserAgent->new();
my $response;
$bing="http://api.bing.net/xml.aspx?";
$appid="AppId=Your Key Here";
$queryurl=$bing . $appid . "&Query=" . $query . "&Sources=Web&Web.FileType=HTML&Web.Count=1";
$response=$request->get($queryurl);
$results=$response->content; die unless $response->is_success;
The $bing variable is used to store the base URL for making an XML request, while the $appid variable is where the developer would insert the AppID associated with their project (note: after the = sign). These variables are then concatenated along with a specification of our query terms, source type, and the optional parameters of file type and results count, to form the complete get request. Results count (the number of results to be returned) can be specified as any number between 1 and 50. For purposes of this program we are limiting the file type to HTML to ensure that links to PDF files, Word documents, etc. are not returned, since in its current form our application would not be able to process these documents. An LWP get request can then be made of the Bing API to request and obtain the search results and store them in the $results variable.
Now that we have an understanding of how documents can be programmatically requested using the Bing API, let’s take a look at the formatting of the API results. Note you can print out the $results variable to do this, or you can enter your get request into any browser to do this. A 1 result query for the term “perl” would yield results as follows (note: Listing 2 somewhat truncated for space issues):
Listing 2: A sample XML response from the Bing API
<SearchResponse Version="2.2">
<Query>
<SearchTerms>perl</SearchTerms>
</Query>
<web:Web>
<web:Total>49800000</web:Total>
<web:Offset>0</web:Offset>
<web:Results>
<web:WebResult>
<web:Title>The Perl Programming Language - www.perl.org</web:Title>
<web:Description>The Perl Programming Language at Perl.org. </web:Description>
<web:Url>http://www.perl.org/</web:Url>
<web:CacheUrl>http://cc.bingj.com/cache.aspx?q=perl&d= </web:CacheUrl>
<web:DisplayUrl>www.perl.org</web:DisplayUrl>
<web:DateTime>2011-10-06T06:55:00Z</web:DateTime>
</web:WebResult>
</web:Results>
</web:Web>
</SearchResponse>
For purposes of the C/C++ code search we will be performing, it is important to note that the information pertaining to each individual result is contained between a set of “web:WebResult” tags and the link to the site referred to in each result is found between a set of “web:Url” tags. Thus, since we want to download the Web page associated with each result to process it for C/C++ code, we could extract the links from the Bing search results as follows (Listing 3):
Listing 3: Using an XML parser to extract links from XML formatted Bing API results.
use XML::LibXML;
my $parser=XML::LibXML->new;
my $domtree=$parser->parse_string($results);
@Records=$domtree->getElementsByTagName("web:WebResult");
my $i=0;
foreach(@Records){
$links[$i]=$Records[$i]->getChildrenByTagName("web:Url");
$i=$i+1;
}
The above code listing makes use of the parsing module XML::LibXML by taking the XML formatted results returned from the Bing API call ($results) and constructing a DOM tree of the results. The DOM tree is then traversed to identify all of the “web:WebResult” nodes and then, in turn, identify each of their corresponding “web:Url” child nodes that contain the links of interest, where they are stored in the @links array.
Creating and Implementing Regular Expressions that Match C/C++ Code
Now that we have an idea of how the Bing search API can be used in conjunction with our search application, it is time for us to consider how the C/C++ code can be extracted from the Web results returned by Bing. The basis behind the extraction will be the creation of a regular expression capable of matching common C/C++ syntaxes. Regular expressions provide a means of defining textual patterns and matching those patterns against blocks of text. For those who are unfamiliar with regular expressions, a tutorial on their usage can be found at (Dev Shed: Parsing and Regular Expression Basics). It is this idea of patterning that enables us to create regular expressions that can match common C/C++ structures, since the syntax of such structures does follow a set pattern. If we consider a typical C/C++ function and a control structure some similarities become evident (Listing 4).
Listing 4: C/C++ Code Syntax Samples
int myfunc ( ){
//code here
}
while ( ) {
//code here
}
In both cases (Listing 4), it is evident that a limited vocabulary precedes a set of parenthesis followed by a set of curly braces. Thus if we establish a set of regular expressions that is capable of matching these patterns, we should be able to pick out most C/C++ code that is wrapped in a function or a control structure. It is important to remember that when attempting such complex pattern matching, there will ALWAYS be false positives and false negatives associated with your results sets. The key is to optimize your regular expressions to obtain the balance between false positives and false negatives that is most in line with your goals. If you are concerned with not missing anything you may choose to use fuzzier expressions that will match more things, but leave you with a higher number of false positives. If you want higher quality matches and care less about missing a few good ones, then it may be in your interest to make the patterns more explicit. The point being that, while the regular expressions used in the sample code work for many cases, some modification may be warranted for your particular usage of them.
Listing 5: Defining the Regular Expressions and Using Them to Extract C/C++ Code
use Text::Balanced qw(extract_codeblock);
#delimiter used to distinguish code blocks for use with Text::Balanced
$delim='{}';
#regex used to match keywords/patterns that precede code blocks
my $regex='(((int|long|double|float|void)\s*?\w{1,25})|if|while|for)';
foreach $link(@links){
$response=$request->get("$link"); # gets Web page
$results=$response->content;
while($results=~s/<script.*?>.*?<\/script>//gsi){}; # filters out Javascript
pos($results)=0;
while($results=~s/.*?($regex\s*?\(.*?\)\s*?)\{/\{/s){
$code=$1 . extract_codeblock($results,$delim);
print OFile "<h3><a href=\"$link\">$link</a></h3> \n";
print OFile "$code" . "\n" . "\n";
}
}
The segment of code in Listing 5 initially loads the Text::Balanced module since this Perl module has the ability of extracting matched sets of quotes, parenthesis, and the like. In this instance we set the delimiter to be used for matching by Text::Balanced to be curly braces, since our C/C++ functions and control structures will be encapsulated in such braces. Next we define a regular expression that is capable of matching the text that could precede any code block comprised of a function or a control structure and store it in the variable $regex. Once this initial setup is complete, the code processed each link by using LWP to request the Web page associated with each link and storing it in the results variable. Next, the Web page is stripped of JavaScript, so that a JavaScript content does not cause false positive matches. After the JavaScript is removed, the “pos” function is used to set the $results string position back to the starting point. $results is then processed with our regular expressions in conjunction with Text::Balanced’s extract_codeblock functionality to identify C/C++ code blocks contained in the Web page text. These identified code blocks are then written to an output file specified by the file handle OFile.
Some sample results of this application can be observed in Figure 1. While in some cases, the greedy nature of Perl’s regular expression can return a bit more than the desired code, overall the application does a great job of extracting the code blocks from Web pages that allow for the rapid pinpointing of Web pages that may provide valuable instruction on how to implement a programming feature of interest. Moreover, while this article focused on the extraction of C/C++ code, the similar syntaxes of other programming languages could allow for the ready adaptation of such techniques to searching for code blocks from other languages such as Java.
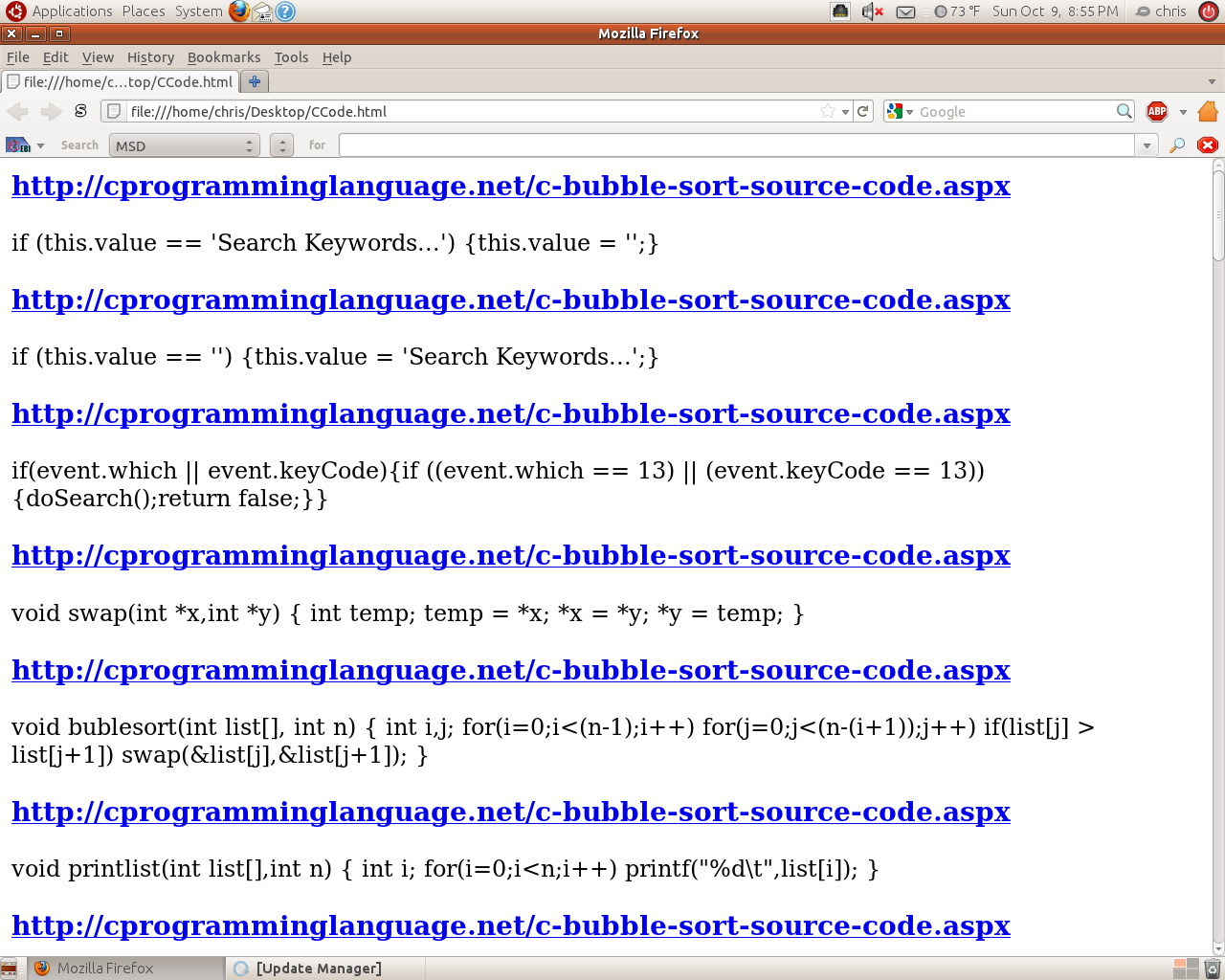
Figure 1: Sample results from the code search application