

Introduction
This article presents a benchmark application which pits the red-black binary tree containers(map, set, etc) against hash containers. This article is not a tutorial on the data structures. For more information on how a red-black binary tree works, you can refer to this wikipedia link. For hash containers, you can read this excellent Codeguru article by Marius Bancila.
Red-black binary tree is a very fast search tree data structure: it can find any item in 4 billion items in 32 steps or less. Its O notation is O(log n) while hash container’s average case is O(1) and its worst case is O(Total number of elements). The only time the hash container’s time-taken-to-search is not O(1) is due to the searched item shares the same hash with other different item(s) and the hash container has to compare them one-by-one to find a exact match. For more information on the performance comparison, look at this Boost library link.
Benchmark
For the map and multimap benchmark, the key in key-value pair is a word(string) in English dictionary while the value in key-value pair is a random number. This is okay because the value is not used in the search. For the set and multiset benchmark, the element is a word(string) in English dictionary. Set is a data structure similar to map without the value pair. The multimap and multiset, unlike map and set, allows the same key/element to be insert more than once and doesn’t enforce the uniqueness. The reason I use std::wstring for the key/element because hash containers has a predefined hash function written for std::wstring. If I use my own custom data types, I may have to write my own custom hash function.
For map, multimap, set and multiset insertion, I called the insert method. For multiset and multimap insertion, I insert the same item twice. For map and set search, I called the find method. For multiset and multimap search, I used equal_range method.
For the benchmark, we will benchmark STL, legacy hash container(more on this later), Visual C++ 10 unordered containers and Boost 1.44 unordered containers. Legacy hash containers which I have just mentioned, exists in the stdext namespace since Visual Studio 2003. We will benchmark them as well to see how they fare against the C++0x unordered containers. By the way, in case you are not aware, C++0x and Boost hash containers are called unordered_xxx(eg, unordered_map). The benchmark application will populate the containers before running the benchmark if it hasn’t been populated but population time is not included in the benchmark results. The reason I did not benchmark the container population is that I found the population to be quite fast.
The benchmark used a random number to index into the std::vector for an item(string) to search in the above containers. You can change the random number generation seed in the benchmark application.
Map Benchmark
The benchmark are done over 5 million searches. The lower the score, the better it is.
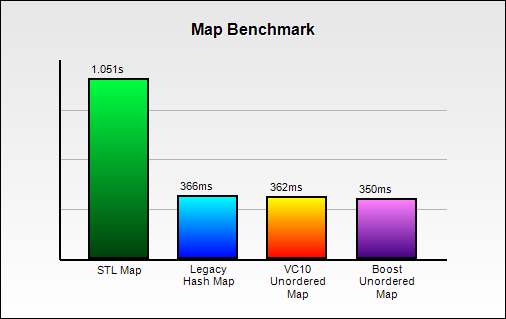
We can see that the hash containers performs 2 times better than STL map. The timing for the hash containers are roughly the same.
MultiMap Benchmark
The benchmark are also done over 5 million searches. The lower the score, the better it is.
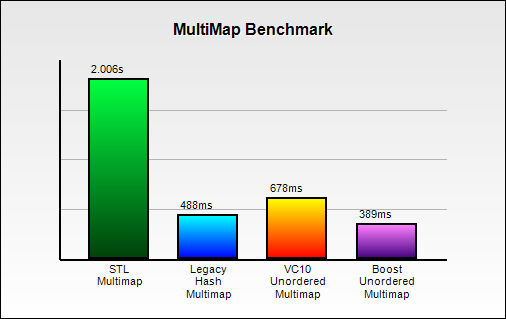
We can see Boost unordered multimap timing is 4 times better than STL multimap.