

A glance of C++0x std::thread
False Sharing and Benchmark
Some other thoughts, helpful resources
A glance of C++0x std::thread
One of the major changes with the new C++ Standard is the support of concurrency —- the new C++ thread library, std::thread. It is said [1] that the library is heavily based upon the existing Boost thread library, many classes and data structures share the same name with the corresponding ones in Boost. One particularly important benefit of using std::thread is the Resource Acquisition Is Initialization (RAII) design, such like the locks: std::lock_guard, std::unique_lock, etc, to ensure that mutexes are unlocked when the current scope is exited. The library efficiency, abstraction penalty, atomic operation, etc, all have been taken care of. For more information, http://www.stdthread.co.uk/doc/ can be a helpful resource.
In this article, I will use the following classes, template classes, and member functions:
std::thread
std::mutex
std::condition_variable
std::unique_lock
std::thread::detach()
condition_variable::notify_one()
condition_variable::wait()
False sharing, examples and benchmark
Processor caches handle blocks of memory called cache lines rather than individual memory locations. Because of this cache-line-sized blocks of memory making of the fundamental units that the Processor caches handle, small size data items in adjacent memory locations will be in the same cache line. Thus if data items in a cache line are independently processed by different threads, the cache hardware will have to play “cache ping pong”. e.g. the cache line is shared by multi processors, and this is called “false sharing” because even the data are processed independently by different processors, the processors have to access the same cache line in turn. This “false sharing” effect can significantly slow down multi-threading execution as we will see in the following example. One solution is structure the data so that data items that are to be accessed by separating threads are far away from each other in cache-line-sized blocks, and the data items more likely to be stored in separate cache lines. As a result, the data process and cache lines access are all independent, and true multi-threading can be achieved.
The following snippet of code illustrates:
A bad designed data structure leads to false sharing. i.e. in class Shared_Work, data n1 and n2 are placed next to each other and most likely are in the same cache line.
An optimized data structure improves the efficiency significantly. A chunk of size 64* char is placed in between n1 and n2 to separate them.
Comparison of the two is shown. Several non-trivial loops run long enough to distinguish the difference between “false sharing case” and “optimized case”.
Environment:,Memory 2.0GiB, 2 cores: Processor 0: Intel(R) Pentium(R) 4 CPU 3.00GHz, Processor 1: Intel(R) Pentium(R) 4 CPU 3.00GHz.
To compile: g++ -O0 -Wall -std=c++0x -pthread falsesharing.cpp
.
Here -std=c++0x is for the std::thread library and -pthread must be linked.
#include <thread>
#include <iostream>
#include <ctime>
#include <memory>
using std::cout;
using std::endl;
const double M=8e8;
//Shared_Work holds the work need to be done
//part1() and part2() separates the work half-and-half
//n1 and n2 are data items
//chunk[64] is the separation attempt.
class Shared_Work {
public:
Shared_Work():n1(1),n2(1),flag1(0),flag2(0) {}
void part1() {
for(; n1<M; n1+=n1%3);
flag1=1;
cond.notify_one();
}
void part2() {
for(; n2<M; n2+=n2%3);
flag2=1;
cond.notify_one();
}
long int result() {
std::unique_lock<std::mutex> lk(mt);
while(flag1==0||flag2==0)
cond.wait(lk);
return n1+n2;
}
private:
std::mutex mt;
std::condition_variable cond;
long int n1;
//char chuck[64];//cache line seperation
long int n2;
bool flag1;
bool flag2;
};
//a template class for generating threads with different member functions
//"action _fptr" will be instantiated by &Shared_Work::part1 and part2.
template<class T>
class Do_Work {
public:
typedef void (T::*action)();
Do_Work(std::shared_ptr<Shared_Work>& x, action y):_p(x),_fptr(y) {}
void operator()() {
(*_p.*_fptr)();
}
private:
std::shared_ptr<Shared_Work> _p;
action _fptr;
};
//single thread work to do
void one_thread() {
long int n1=1, n2=1;
for(; n1<M; n1+=n1%3);
for(; n2<M; n2+=n2%3);
cout<<n1+n2<<endl;
}
time_t start, end;
double diff;
int main(int argc, char* argv[]) {
std::shared_ptr<Shared_Work> p(new Shared_Work);
Do_Work<Shared_Work> d1(p, &Shared_Work::part1);
Do_Work<Shared_Work> d2(p, &Shared_Work::part2);
time(&start);
std::thread t1( d1 );
std::thread t2( d2 );
t1.detach();//release the ownership to C++ runtime library.
t2.detach();//release the ownership to C++ runtime library.
cout<<p->result()<<endl;
time(&end);
diff=difftime(end, start);
cout<<diff<<" seconds elapsed for 2 threads calculation."<<endl;
time(&start);
one_thread();
time(&end);
diff=difftime(end, start);
cout<<diff<<" seconds elapsed for 1 thread calculation."<<endl;
}
The cache-line-sized blocks memory are typically 32 or 64 bytes in size, so the chunk is set to be: Shared_Work::chunk[64]. First, the “char chunk[64]” line is commented out. The running result is shown in the following figure.
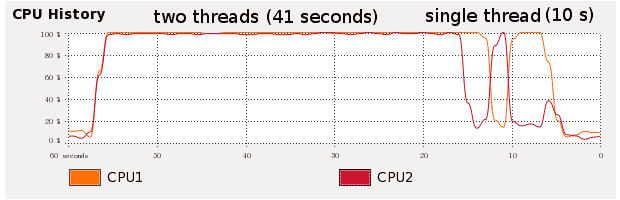
As can be seen, the multi-threading performance (41 seconds) now is far more inefficient than single threading (10 seconds). Although the processors are running to their most, false sharing induced cache ping pong introduces significant amount of redundant instructions.
Now let’s add “char chunk[64]” to the code and the result is shown in the following figure.
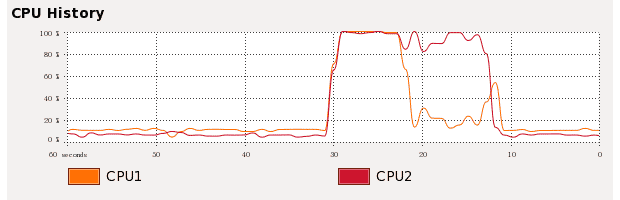
Now, multi-threading consume 8 seconds and single threading consumes 10 seconds. We get 20% improvement using multi-threading! And because now the chuck[64] separates the data n1 and n2.
Some other thoughts, helpful resources
1. If the -O3 is turned on in g++, it seems to me that the chunk[64] is not needed and compiler can place the n1 and n2 in different cache line automatically.
2. If n1 and n2 are not int, but double, and the operations such like “n1%3″are changed to “(long long int) n1%3”, then the multi-threading performance is going to be almost twice as fast as single threading case. My guess is that the cpu will bind the calculation more tightly in this case and “cpu affinity” [2] can play a key role now.
3. It seems there is no ” semophore” in std::thread and I asked Anthony Williams who is the author of the c++ thread library. Here is his reply:
“A semaphore is a low-level, multi-purpose synchronization tool. As such it is hard to use correctly. The C++ thread library does not provide a semaphore. Instead it provides the things you would build with semaphores — mutexes, condition variables and futures. ”
4. For more information, you can go to
http://www.justsoftwaresolutions.co.uk/publications.html
or register to be Anthony’s blog reader at:
http://www.justsoftwaresolutions.co.uk/2010/07/
Reference:
[1]http://www.stdthread.co.uk/
[2]http://www.linuxjournal.com/article/6799
Addendum:
to time the time consumption, clock() is not used here. Because clock() will count the cpu ticks and not the real time. In multi-core case, clock() will count all cpu ticks and thus not a good candidate to do real world timing. If more precise timing is needed, the timer function has to be carefully picked for particular operation systems, but the C++ standard library, so far as i know, doesn’t provide a universal one that can count to millisecond.