

Most of the data types supported by programming languages span on more than one byte, leading to a problem: How do we store these bytes in memory? As in the case of most problems, there is more than just one solution, and of course, they are all used. The answer has separated the world of computing (mainly) in two: those who adopted the little-endian layout, and those who adopted the big-endian representation.
Data Storing Solutions
We often like to envision memory as a contiguous array of locations (each one identified by an address), lining up in a row, with the leftmost starting from address 0, and the rightmost having the address N-1 (where the total number of bytes of memory is N).

Now, take the example of type int/integer, represented on 4 bytes on a 32-bit platform machine. When it comes to storing it in memory, there are two widely used solutions.
In the little-endian representation, bytes are arrayed in memory, with the least significant byte at the lowest address (left-most memory location). For instance, if you need to store the integer 0x12345678 (hexadecimal value), the least significant byte (0x78) is stored at the left-most memory location, lowest address, base+0, and the most significant byte (0x12) is stored at the right-most memory location (out of the four needed), base+3.
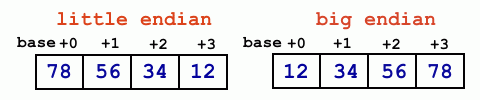
In the big-endian representation, everything is reversed. The most significant byte (0x12 for the previous example) is stored at the left-most memory location, lowest address, base+0, and the least significant byte at the right-most address, base+3.
But of course, that’s not all. Middle-endian is used on some platforms, and the position of bytes can vary. A PDP-11 processor stores the integer 0x12345678 as 0x34, 0x12, 0x78, 0x56 (from left to right).
There are architectures that can be configured to work either with big-endian or with little-endian (ARM, DEC Alpha, MIPS, PA-RISC, and IA64). Those are referred as bytesexual or bi-endian. On some architectures, the endianness can be switched by software (usually at start-up); on others, the endianness is selected by some hardware on the motherboard (and sometimes cannot be changed by software).
The endianness applies not only to the order of bytes in memory, but also to the numbering of bits in a byte (a word, or a double-word). In the case of a big-endian architecture, the bits are numbered from left, with bit 0 being the most significant one, and bit 7 (at the most-right position) being the least significant one. On the other hand, with a little-endian architecture, the bits are numbered from right to left, the least significant one (at the right) being bit 0, and the most significant one (at the left) being the bit 7.
And guess what: The representation of dates on different areas on the planet is subjected to the same endianness, but instead of being about bytes, is about days, months and years:
- US: middle-endian representation: mm/dd/yy
- Europe: little-endian representation: dd/mm/yy
- Japan: big-endian: yy/mm/dd
The Origin of the Terminology
In case you wonder where the names come from, the answer may surprise you: from Jonathan Swift‘s Gulliver’s Travels book. In the first part of the book, Gulliver, an English sailor, awakes after a shipwreck as a prisoner of a six-inch high people, called Lilliputians. In Chapter 4 of the book, a secretary of the emperor of Lilliput tells him about the war with the people of Blefuscu, a rival empire, who offered protection for the Big-Endians in the civil war between the Big- and Little-Endians. It was the primitive way in Lilliput that the eggs were broken from the larger end before being eaten. But, when the son of an emperor (that later become emperor himself) cut his finger breaking an egg, his father, the emperor, published an edict, commanding everyone, under great penalties, to break the eggs from the little end. And that edict led to a great civil war between the followers of the new way (the Little-Endians) and those who remained committed to the old way (the Big-Endians). In the torment of the conflict, the Big-Endians found protection in the Kingdom of Blefuscu and a war was started between the mighty Kingdoms of Lilliput and Blefuscu.

A quote from Chapter 4 of the book:
It began upon the following Occasion. It is allowed on all Hands, that the primitive way of breaking Eggs, before we eat them, was upon the larger End: But his present Majesty’s Grand-father, while he was a Boy, going to eat an Egg, and breaking it according to the ancient Practice, happened to cut one of his Fingers. Whereupon the Emperor his Father published an Edict, commanding all his Subjects, upon great Penaltys, to break the smaller End of their Eggs. The People so highly resented this Law, that our Histories tell us there have been six Rebellions raised on that account; wherein one Emperor lost his Life, and another his Crown. These civil Commotions were constantly fomented by the Monarchs of Blefuscu; and when they were quelled, the Exiles always fled for Refuge to that Empire.
The Best Representation
Actually, there is no such thing. Although many have taken either one side or the other, both little-endian and big-endian representations have advantages and disadvantages.
For little-endian, the assembly language instructions that work with different length numbers (1, 2, 4 bytes) proceed in the same way by first picking up the least significant byte, at address base+0 and going towards the most significant byte.
With a big-endian representation, no matter how long the number is, you can quickly test if it is positive or negative by checking the byte at address base+0 (the most significant byte). Most network header code and bitmap graphics are mapped with a big-endian order. On a big-endian machine, the shifts and stores are automatically taken care by the architecture; but on a little-endian machine, there is a need to reverse the byte order of elements that are stored on more than one byte. Moreover, it is easier to read hexadecimal texts.
Endianness on Different Architectures
The following architectures use:
- Little-endian:
- Intel x86
- AMD64
- DEC VAX
- MOS Technology 6502
- Big-endian
- Sun SPARC
- Motorola 68000
- POWER PC
- IBM System/360
- Bi-endian, running in big-endian mode by default:
- MIPS running IRIX
- PA-RISC
- Most POWER and PowerPC systems
- Bi-endian, running in little-endian mode by default:
- MIPS running Ultrix
- most DEC Alpha
- IA-64 running Linux
Implications of Endianness
When you write software that runs on a single machine, usually you do not care for the endianness. When the machine is part of a network, with other machines using different architectures, and the software communicates with others in this network, a transformation must be applied before sending, or after reading data.
However, there are cases when you care for endianness even if your software runs on a single machine. Different file formats use different endianness. For instance, the JPEG format uses big-endian representation, so if you write a program that saves JPEG images and runs on a little-endian machine, you must reverse all the bytes before writing it to disk.
The following table shows the endian order for some files:
| File | Endianness |
|---|---|
| Adobe Photoshop | Big Endian |
| BMP (Windows and OS/2 Bitmaps) | Little Endian |
| DXF (AutoCad) | Variable |
| GIF | Little Endian |
| IMG (GEM Raster) | Big Endian |
| JPEG | Big Endian |
| FLI (Autodesk Animator) | Little Endian |
| MacPaint | Big Endian |
| PCX (PC Paintbrush) | Little Endian |
| QTM (Quicktime Movies) | Little Endian |
| Microsoft RIFF (.WAV & .AVI) | Both |
| Microsoft RTF (Rich Text Format) | Little Endian |
| SGI (Silicon Graphics) | Big Endian |
| Sun Raster | Big Endian |
| TGA (Targa) | Little Endian |
| TIFF | Both, Endian identifier encoded into file |
| WPG (WordPerfect Graphics Metafile) | Big Endian |
| XWD (X Window Dump) | Both, Endian identifier encoded into file |
A UNICODE text file encoded in UTF-8, UTF-16, or UTF-32 has a special marker at the beginning, called a Byte-Order-Mask (BOM), that indicates whether the file uses little-endian or big-endian byte order.
| BOM | Encoding |
|---|---|
| EF BB BF | UTF-8 |
| FE FF | UTF-16 (big-endian) |
| FF FE | UTF-16 (little-endian) |
| 00 00 FE FF | UTF-32 (big-endian) |
| FF FE 00 00 | UTF-32 (little-endian) |
Conversion from Little-Endian to Big-Endian
The following function swaps the 4 bytes of an integer (32-bit platform) and can be used to convert from the little-endian representation to big-endian and vice versa.
unsigned int swap(unsigned int value)
{
return ((value & 0xFF000000) >> 24) |
(((value & 0x00FF0000) >> 16) << 8) |
(((value & 0x0000FF00) >> 8) << 16) |
((value & 0x000000FF) << 24);
}
But, you don’t have to write conversion functions to deal with data that is transferred on a TCP/IP network that uses the big-endian ordering of bytes. There is a series of library functions that convert the host representation to the network representation: